v0 APIのアーキテクチャ: Chat Completion API自作界隈
はじめに
先日、Vercelがv0 APIという興味深いサービスを発表しました。v0.devは、アプリのプロトタイピングからデプロイまでをWebブラウザ上のチャットで行えるサービスです。v0 APIは、この機能を外部から利用可能にする有料プラン向けのAPIサービスとして提供されています。
現在、CursorやClineなどのエディタでコード生成のバックエンドとしてv0 APIを利用することができます。くわえて、Vercel ProユーザーはAI SDKのAI Playgroundからこの機能を試すこともできます。
利用方法
v0 APIは、OpenAIのChat Completions APIの仕様に準拠したエンドポイントを提供しています。そのため、既存のOpenAIモデル対応アプリケーションでは、ベースURLの設定を変更するだけでv0 APIを利用することができます。
ユーザーにとっては、AIエディタに設定を追加するだけで、Next.jsアプリなどのモダンなWebアプリケーション開発において、コード生成の品質が大幅に向上するという利点があります。
Clineでの設定方法が以下のページにあります。 Base URL: https://api.v0.dev/v1とAPIキーを設定するだけで使えます。
LLMをコード生成に使う時の課題
現在のフロンティアモデル(ClaudeやGemini)は知識カットオフにより2024年前半頃の技術スタックで学習が停止しており、2024年後半以降にリリースされたReact 19、Next.js 15、Tailwind CSS 4.0、shadcn/ui、AI SDKなどの最新アップデートに対応していません。このため、新規にアプリケーションのコードを生成する際、最新のフレームワークバージョンと組み合わせると動作に問題が発生することがあります。
また、v0のようなモダンなWebアプリのコード生成というユースケースに、LLMは特化して設計されているわけではありません。LLMの性能評価で使用されるベンチマークは、Pythonのデータサイエンスやアルゴリズム問題が中心であり、最も活躍が期待される場面はチャットアシスタントでのコードサンプル提供です。
自然言語による指示でアプリのプロトタイピングを行うv0では、生成されたコードの品質がすべてです。しかし、従来のLLMはエージェントのようにエラー修正を自律的に行うことができません。そのため、v0ユーザーはエラーを発見した際に、手動で修正指示を入力する必要がありました。
このような課題を解決するため、Vercelは複合モデルアーキテクチャを開発したというのが、以下のブログ記事の内容です。
v0 APIのアーキテクチャ
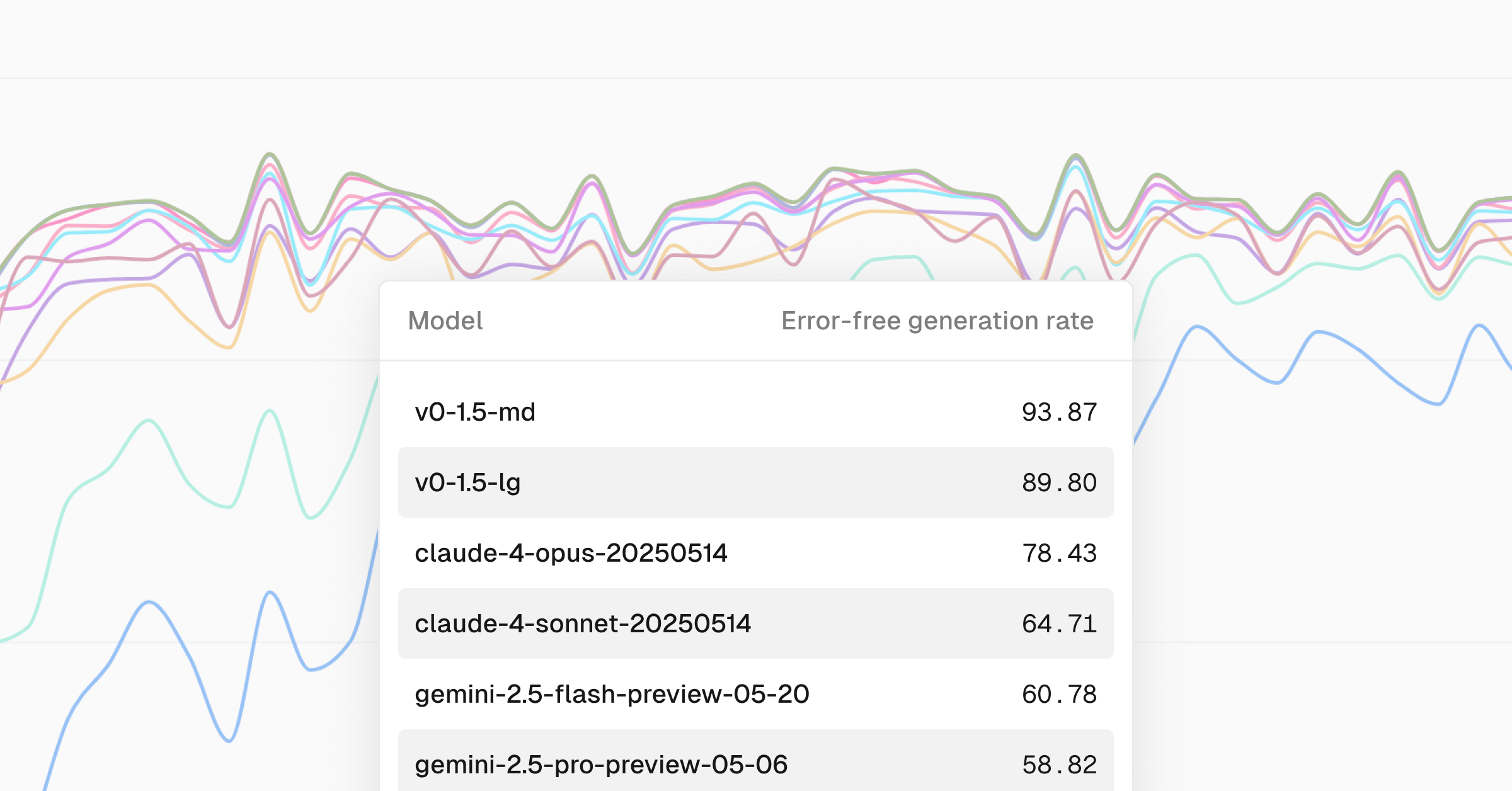
Vercelはv0 APIを「v0モデル」という新たなLLMのような名称でマーケティングしています。"v0-1.0-md"や"v0-1.5-md"のようにバージョンごとに専用のモデル名が付けられていますが、実際にはv0モデルは独立したLLMではありません。
v0モデルは内部でClaude(Anthropic Sonnet 3.7やSonnet 4)などの既存のLLMのAPIを呼び出し、それらの結果を活用する仕組みになっています。Vercelはこのアプローチを複合モデルアーキテクチャ(Composite Model Architecture)と呼んでいます。
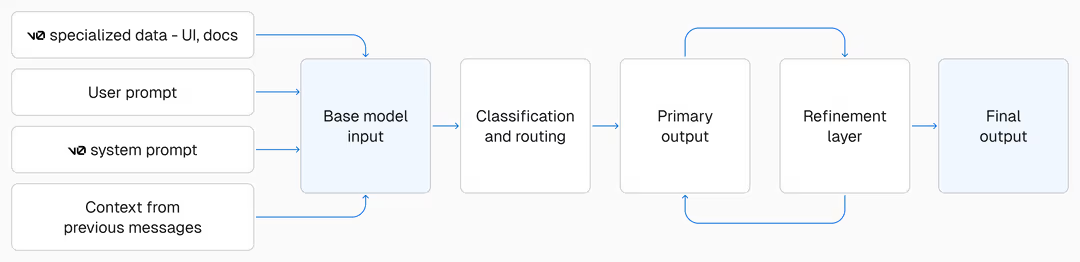
この複合モデルアーキテクチャでは、LLMの呼び出しプロセスが下図のようにいくつかの段階に分けられています。
前処理(Pre-processing)
まず前処理として、Vercelはv0ユーザーが送信したクエリを受け取り、自社データセットから最適なドキュメントを検索してLLMの入力コンテキストに追加します。Vercel内部のDBなどからも情報を取得しているようです。これをRAG(Retrieval-Augmented Generation)の文脈で説明していました。
メインのコード生成
次にメインのコード生成では、ベースLLMとしてClaude Sonnet(v0-1.0-mdではSonnet 3.7、v0-1.5-mdではSonnet 4)を使用していることが言及されています。ここが普段私たちが意識しているコード生成のレイヤーです。
後処理(AutoFix)
後処理として、LLMが生成したコードをレスポンスとして返す前に自動修正を行います。VercelはこれをAutoFixと呼んでおり、過去にはGemini Flash 2.0を使用していましたが、現在は独自にファインチューニングした言語モデル「vercel-autofixer-01」をFireworks AI上でホストして使用しています(基盤モデルは非公表)。
このAutoFixモデルは、コード生成中にリアルタイムでエラーや不整合を修正します。AIエディタ側で行われていたようなフィードバックループがサーバー側に来ているということですね。
アーキテクチャの特徴
このように、v0 APIは既存のLLMを単純にラップするのではなく、前処理・後処理や複数のモデルを組み合わせることで、最新のフレームワークやツールに対応したコード生成を実現しています。
OpenAI互換エンドポイントとして提供されているため、既存のAIエディタやツールへの統合も容易です。MCPサーバーでコンテキストを追加する方法と比較すると、メッセージデータに直接介入している点に特徴があります。
AIエディタが用意したカスタマイズ設定を活用してサービスを提供するという設計思想もユニークだと思いました。
Chat Completions API を自作しよう
このように、v0 APIはLLMの応答に前処理・後処理を組み合わせることで、コード生成の品質を大幅に改善する仕組みを採用しています。
LLMをコード生成に使用する際の課題は、私たちが日常的にAIエディタでコーディングを行う場面でも同様に発生します。
そこで、v0 APIの仕組みを参考に、私たちも独自のChat Completions APIプロキシを構築し、ClineやCursorなどのAIエディタから呼び出せるようにしてみましょう。
API設計と基本実装
自作APIは、クライアント(VSCodeやCursor)とLLMサービスの間に立つプロキシとして機能します。Chat Completions API互換のREST APIとして実装し、POST /chat/completions エンドポイントでリクエストを受け取り、ストリーミング対応でレスポンスを返します。デバッグ用に非ストリーミングオプションを用意しておきますが、現在のAIエディタからの呼び出しはほぼストリームです。
実装は段階的に進めます。まずモックレスポンスで動作確認を行い、次にOpenAI SDKを使って真の(?)LLM呼び出しに置き換えます。フレームワークにはHonoとcreate-cloudflareを採用し、ボイラープレートを最小限に抑えた軽量な実装を目指します。詳細なコードサンプルは以下のGistリンクを参照してください。

モックレスポンス版(mock.ts)は単に"Hello, I'm Mock Streaming!"という返事のみの固定のJSONデータをストリーミングで返します。HonoのAPIによって以下のように簡単に書けますね。
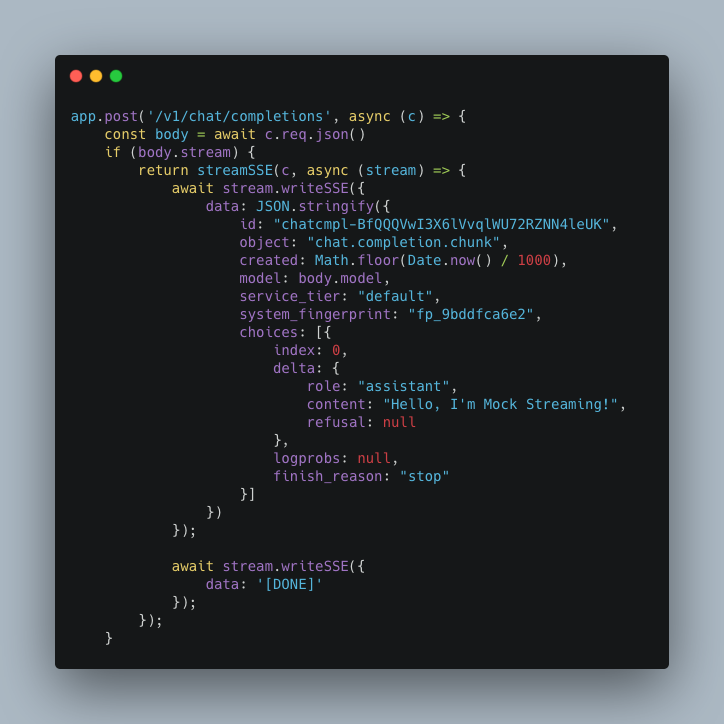
これをwrangler devで立ち上げたローカルサーバーのエンドポイントhttp://localhost:8787/mock/v1 でアクセスできるようClineに設定します。
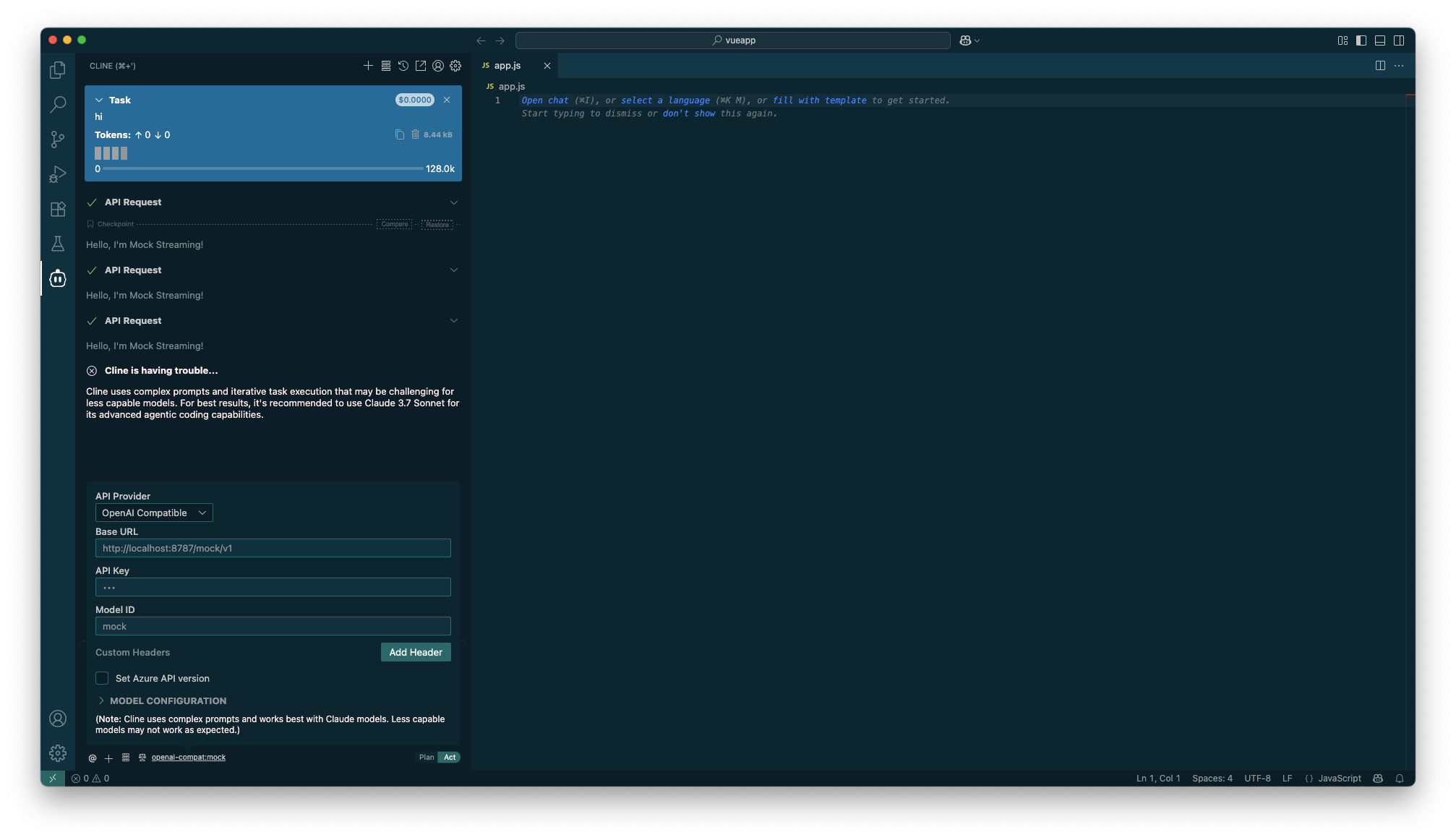
モックレスポンス版をClineに組み込むと、APIは常に固定のメッセージを返します。ローカルサーバーによりClineの応答速度が格段に向上するので、通常の利用時はLLMのAPI呼び出しのレイテンシがボトルネックだったことを実感できました。
そしてClineはモックAPIの単調な応答に対して「インテリジェンスが足りないためClaude Sonnetへの置き換えを検討してください」と促してきます。このメッセージも初めて見ました。
次にOpenAI版(openai.ts)です。差分は単に入力→出力をそのままOpenAIのSDKに渡すだけで、完全なプロキシサーバーになります。
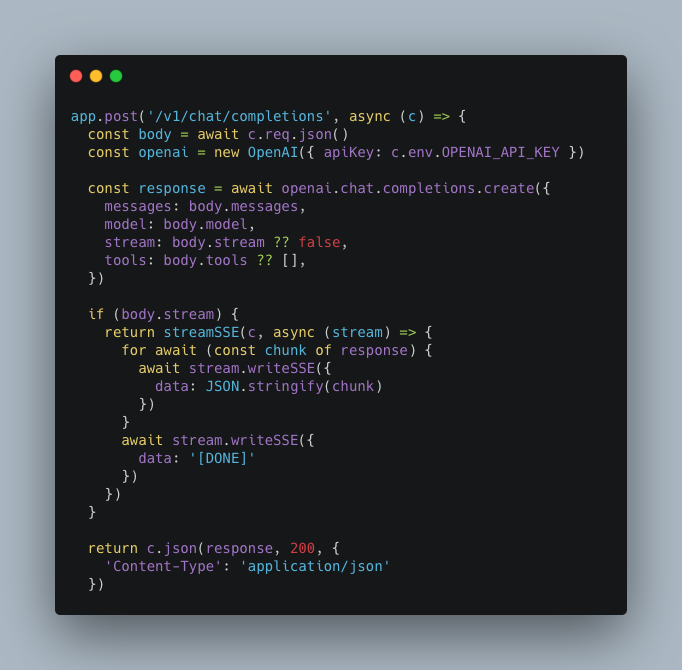
これを先ほどのモックAPIのエンドポイントと入れ替え http://localhost:8787/openai/v1 にモデルIDをgpt-4o などに指定するといつものClineのように動作します。ただここまでだとリクエストをそのまま流して何が嬉しいのか? と思いますよね。次の段階ではv0 APIのように前処理工程を加えてゆきます。
LLMのコンテキストを動的に注入する
OpenAI APIでコード生成するの前処理として、v0 APIのように私たちのAPIでも、フレームワークのベストプラクティスをメッセージオブジェクトとして追加してみましょう。たとえば以下のようにファイルに保存したプロンプトを追加で上乗せします。Clineから見ると自身の知らぬところで勝手に設定コンテキストが追加されていることになります。
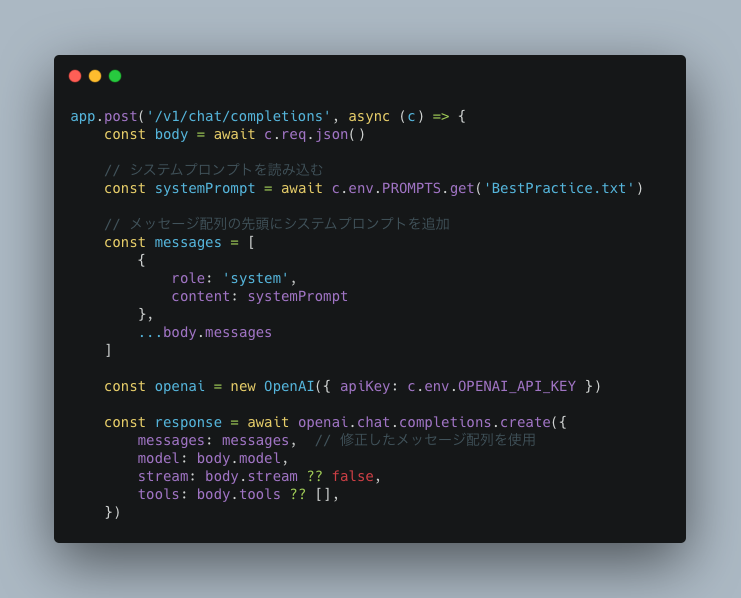
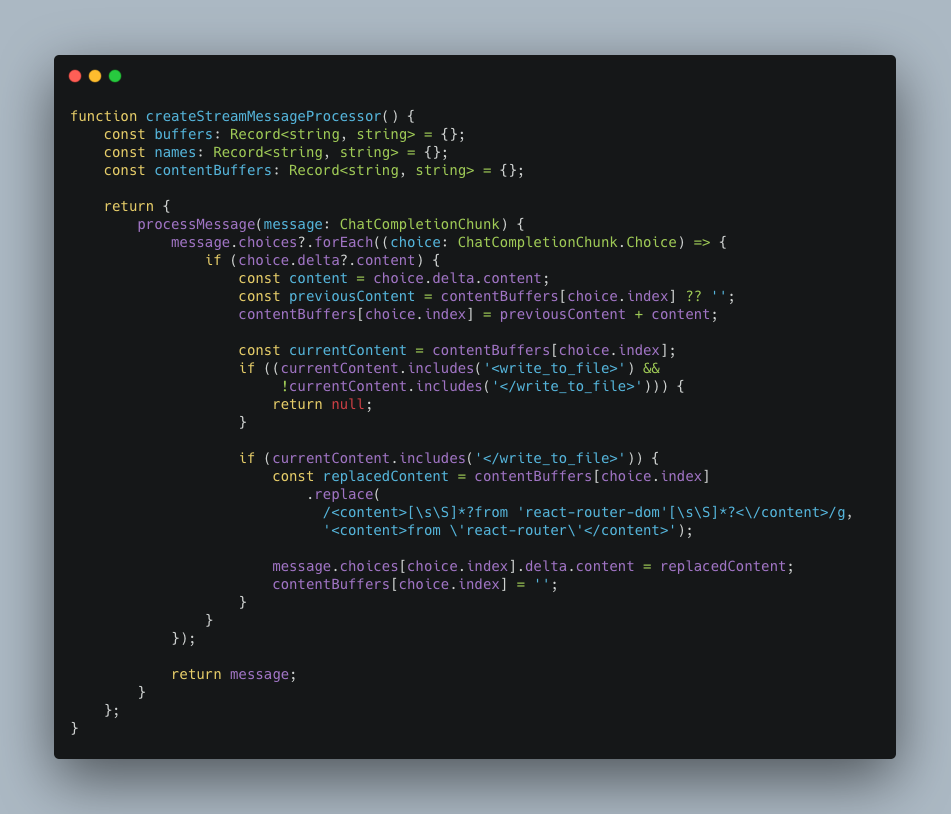
レスポンスのチャンクを書き換える
生成されたコードをユーザーに返却する前に、ストリーミングレスポンスのチャンクを書き換えることで、AIエディタの挙動を動的に制御できます。
たとえば、レスポンスのメッセージ配列の中にあるファイル編集ツールの呼び出しを検知します。その内部のスニペットを探索し、古いメソッドを使っていたら新しいメソッドに置換するというシンプルなパイプラインが構築できます。
これは以下のようにストリームデータを逐次受信しつつ、必要な変換処理を挟みながらクライアントに転送していくことで実現できます。
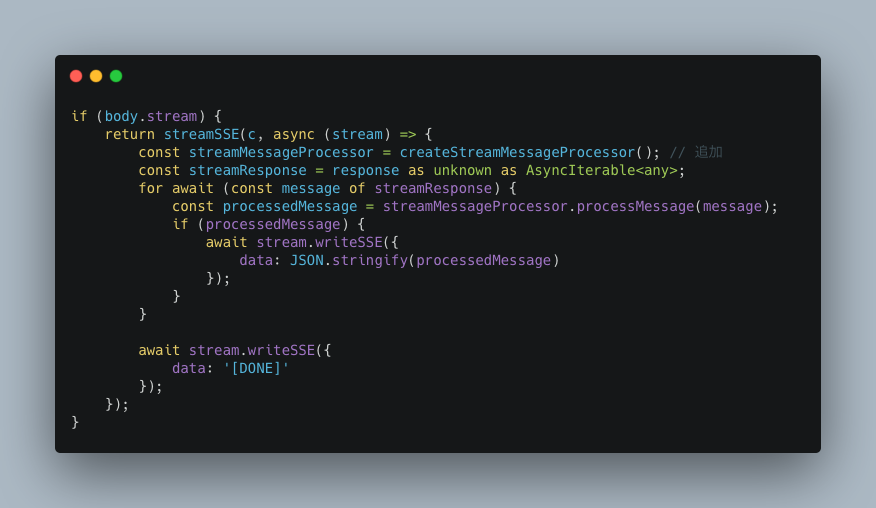
モデルをWorkers AIへの置き換える
v0 APIの複合モデルアーキテクチャは、内部で呼び出すLLMを動的に切り替える仕組みを備えています。これと同様の機能を実現するため、先ほど実装したOpenAI APIの呼び出し部分をCloudflareのWorkers AIに置き換えてみます。
Workers AIはCloudflareが提供するサーバーレスでAIモデルを実行できるサービスで、Cloudflare Workersから簡単に呼び出せます。LlamaやMistralなどの最新のオープンなモデルにできます。ローカルPCでパラメータサイズの大きいモデルを動作させるより遥かに高速で、無料枠で試せますので多様なモデルを切り替えて呼び出したい本記事のケースに最適です。
ただし、Workers AIはwrangler devで立ち上げたローカルサーバーにも対応していますが、実際にはCloudflare内のサービスをリモートで呼び出しているため、利用枠(Neurons)を消費する点に注意が必要です。
モデル選択の考慮点
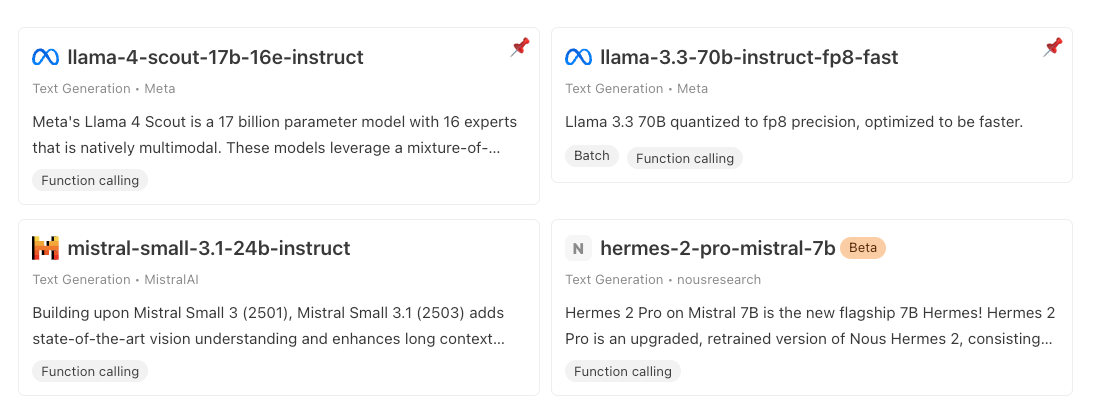
モデルの選択については、Workers AIで現在Function Calling(tools)に対応したモデルはいくつかあり、その中でもllama-4-scout-17b-16e-instructが最も忠実にツール呼び出しの応答がされることを確認しました。
他のモデルは正常なデータ構造やテキストの応答を返さないことが多く、動作検証に耐えられません。
llama-4-scout-17b-16e-instructは十分な性能を備えていますが、残念ながらこのモデルは日本語での出力に対応していません。
各モデルの応答はPlaygroundから試すことができます。日々新しいモデルが追加されているので、今後より動作に適したモデルが追加されるかもしれません。
Workers AIへの実装
先程実装したOpenAIのAPI呼び出し部分をWorkers AI用に置き換えます。
Workers AIのレスポンスはOpenAIとは異なるため変換処理が必要であり、この変換パイプラインは「レスポンスのチャンクを書き換える」で説明したv0の後処理フローと同じ仕組みです。
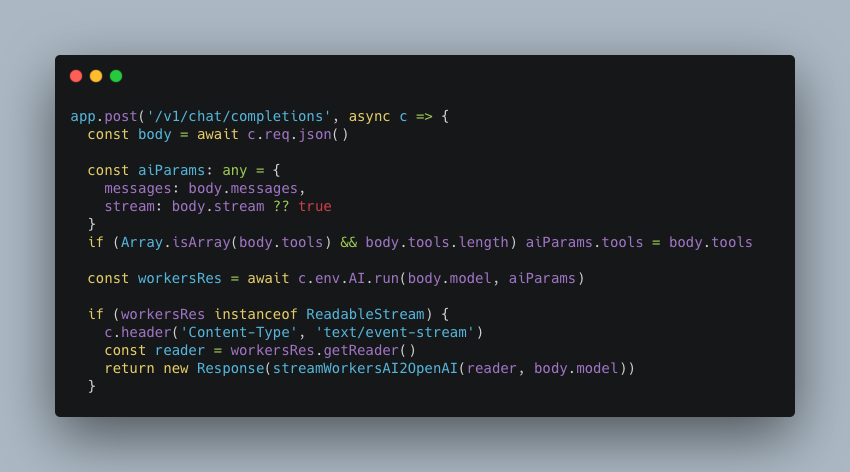
streamWorkersAI2OpenAI の工程はかなり骨が折れる作業でした。基本的にデータ構造の移し替えなのですが、Workers AIのレスポンス仕様→OpenAIのレスポンス仕様→Clineのクライアント仕様の階層を辿るのでデバッグを人間が真心を込めて行う必要がありました。筆者はHTTPクライアントツールなどを駆使して各リクエストの中身の値を観察してロジックを組みました。
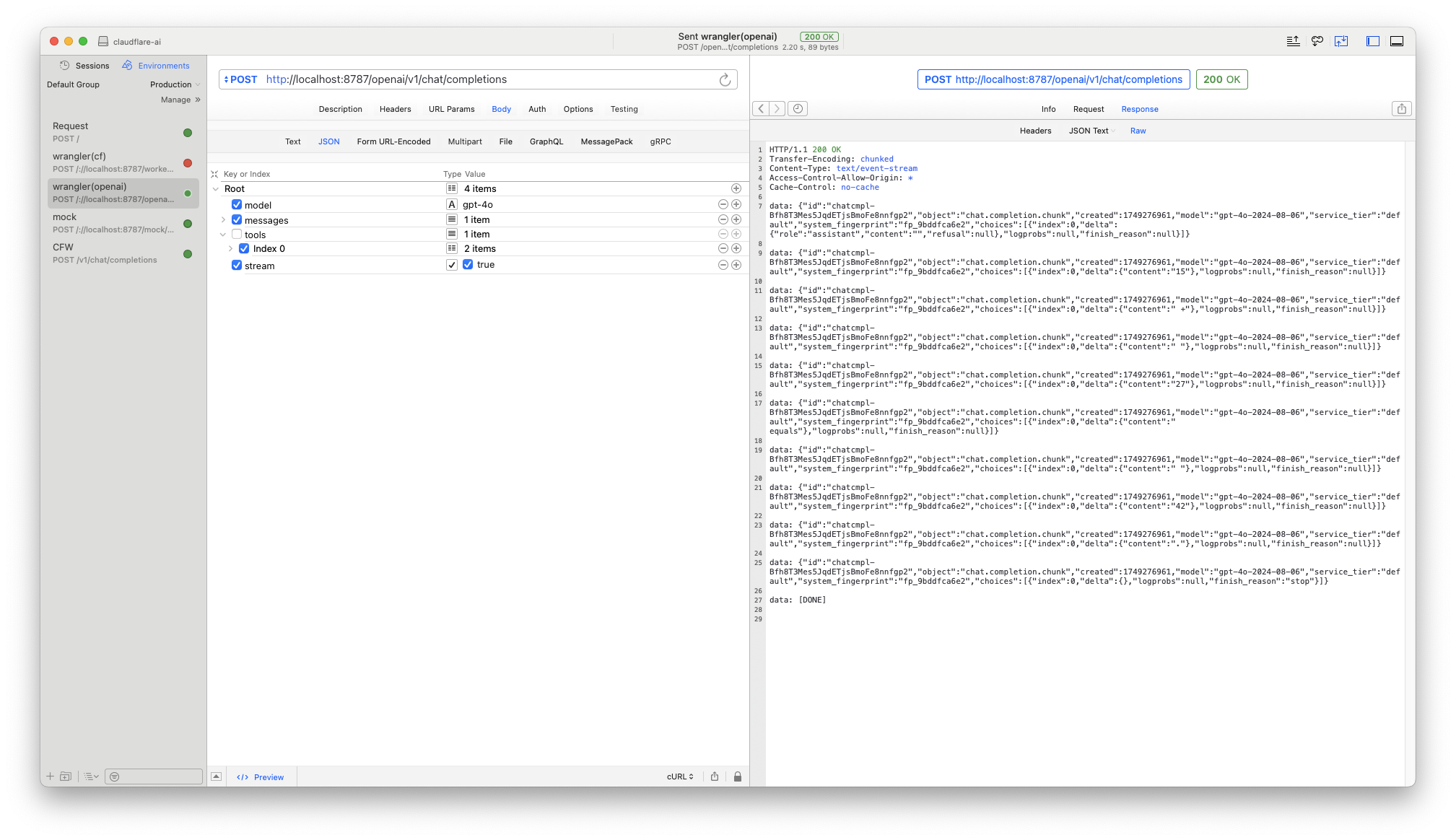
エンドポイントをhttp://localhost:8787/workersai/v1 に差し替えClineのエージェントが無事に機能することを確認しました。
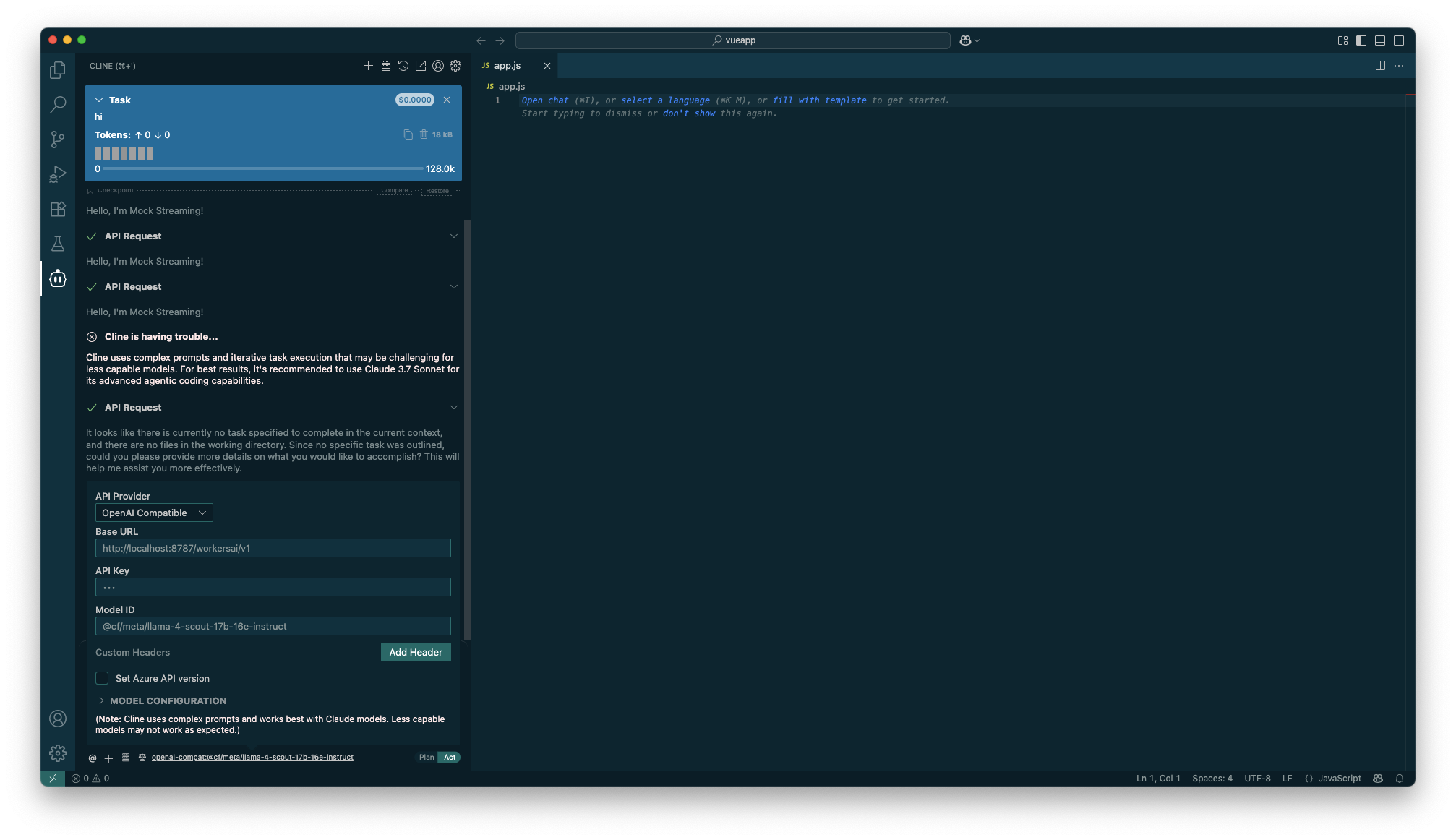
おわりに
本記事では、Chat Completions API互換の自作APIを設計・実装し、OpenAIやWorkers AIなど複数のLLMサービスに対応させる方法を解説しました。モック実装から始めて段階的に機能を拡張し、ストリーミングレスポンスやレスポンス変換、動的なコンテキスト注入などのポイントを紹介しました。
Clineでの動作に焦点を当てましたが、筆者は他のエディタでも動作確認ができています。
CursorではCloudflare Workersにデプロイしたオンラインのエンドポイントが必要になります。これはCursorの仕様でCursor社の内部インフラを経由するためです。そのため、アクセスを制限するために、アクセスを制限するには自前のAPIキー認証の実装が必要になります。
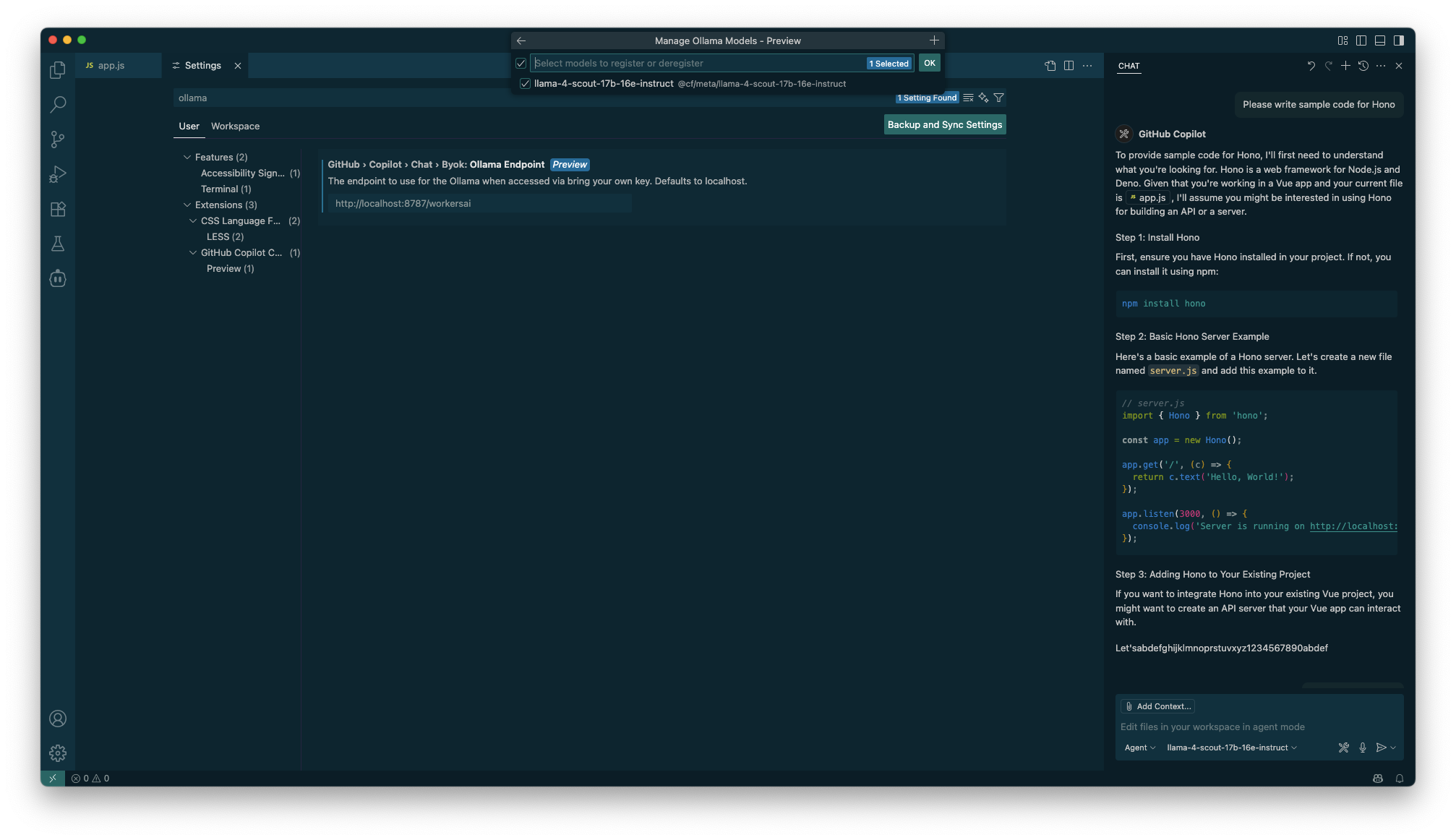
また、GitHub Copilot Chatはv1.99以降でOllamaエンドポイント設定に対応しており、Ollamaのモデル情報を返すエンドポイントの追加が必要ですがClineと同じく動作します。こちらはローカルホストのAPIを想定した機能のためAPIキー設定は不要です。
これらの実装も以下のソースコードに含まれています。

v0 APIの複合モデルアーキテクチャはv0と似たシステムを構築したいケースでの応用が考えられます。たとえばデザインシステムや社内ドキュメントを活用したコードプロトタイプ生成があります。これはMCPサーバーの活用方法として開発の現場で検証されているような領域で、業界の関心も高いです。
本記事が、独自のChat Completions APIプロキシや複合モデルアーキテクチャの設計・実装に取り組む際の参考になれば幸いです。