ts-bench v2: 数十万行規模のTypeScript製アプリの修正タスクでコーディングエージェントの性能を測る
筆者は以前よりts-benchというAIコーディングエージェントのベンチマークを作っています。
このたびv2に移行したので、その背景と設計、そして今後どう継続していくかを書きます。
なお、本記事に出てくるスコアやティアは2026年4月に試験的に回した一回分のスナップショットです。
最新ではないし、モデルやエージェント製品、評価コードが更新されれば順位は動きます。
「Opusには解けず、Sonnetには解けた課題があった」といった観測も、現時点では結論ではなく途中経過として読んでください
ハーネスという用語の整理
この記事では、エージェントハーネスを、大規模言語モデル(LLM)にプロンプトを渡し、ツールを呼ばせ、ファイルを編集させ、テストを実行させる実行系の意味で使います。
Claude CodeやCodex CLI、Nano Code、opencodeのような部分です。
一方で、評価ハーネスは、タスク、Docker環境、正解判定、スコア集計をまとめた測定側のしくみを指します。
ts-benchは評価ハーネスであり、その中で呼び出すエージェントハーネスを差し替えられるようにしています。
なぜベンチマークを自作するのか
ベンチマークなら、AnthropicやOpenAIのようなモデル開発企業が公式スコアを出しています。
それでも自分で測りたい理由が筆者には3つあります。
ひとつは、自分でエージェントハーネスを書くときの評価基準が欲しいからです。
筆者は『作って学ぶAIエージェント』という本で、Claude CodeやCodex CLIと同種のしくみを持つ小さな自作エージェント Nano Code を一から組み上げました。
こうして自分でエージェントの実行系を書くようになると、改造して良くなったのか悪くなったのかを、感覚ではなく数字で確かめたくなります。
LLMは毎回同じ答えを返すとは限らないので、ソースコードや設計の変更がどのような結果をもたらすのか、すぐにはわかりません。
サブエージェント、エージェントスキル、システムプロンプト、ツール定義のような介入は、便利に見えても別のタスクでは悪化を招くことがあります。
その本のなかでも書いたとおり、同じモデルでもエージェントハーネスの実装次第で挙動は大きく変わります。
だからこそ、エージェントハーネスの良し悪しを測るものさしが要るわけです。
ふたつめは、新しいモデルが出たときに、自分のエージェントハーネスと組み合わせた状態で性能を検証したいからです。
モデル単体の性能と、それを自分の環境で動かしたときの性能は別物です。
みっつめは、開発元が出すスコアより、自分が日常的に使うユースケースで測った数字の方が信用できるからです。
ベンダーのベンチは自社に都合のいい条件で測られがちですし、何より「私が普段やっている作業」とは違います。
世の中の多くのSWEベンチ系の評価は、モデル同士を公平に比べるために、全モデルを同一の標準エージェントハーネス(たとえば mini-SWE-agent)に載せて測ります。
これはこれで意味のある計測です。
しかし私たちが実際に使うのは標準エージェントハーネスではなく、Claude CodeやCodex、Copilot CLIといった個別のエージェント製品です。
同じモデルでも、どのエージェントに載せるかで結果は変わります。
ts-benchが測りたいのは、その普段使う組み合わせそのままの性能です。
この思想は、後で述べる再現性、サブスクリプション対応、独自データセット化の話にもつながっています。
なぜ v1 から v2 へするのか
v1ではExercismのTypeScript練習問題を使っていました。
Exercismは、各言語の小さな練習問題を解きながらプログラミングを学ぶためのサービスです。
この選択は、aiderのベンチマークも参考にしていました。
現在はAider Polyglotとして知られているベンチマークの前身も、Exercismの問題を使って、LLMが自然言語の指示から既存コードを編集し、テストを通せるかを測っていたからです。
しかしこれは簡単すぎて、いまの最先端モデルは軒並み満点で解いてしまいます。
差がつかなければベンチマークとして機能しません。
もっと難しい、実務に近い問題が必要になりました。
これは筆者だけの感覚ではありません。
v1を使い込んでいたユーザーからも、「満点が当たり前になってきたので比較が難しい」「より難易度の高いタスクじゃないと優劣をつけられない領域に来てしまった」という声が上がっていました。
VRAM 24GBで動くローカルLLMさえv1で満点を取るようになり、「v1の役目はかなり果たしたのではないか」と感じるところまで来ていました。
うれしい変化ですが、だからこそもっと難しい土俵が要るという話です。
aiderも同じ問題に直面していました。
2024年末に公開されたAider Polyglotは、元のPython 133問ベンチが上位モデルで80%を超えて飽和し、1問か2問の差で順位が動くようになったことを理由に作られています。
新しいpolyglot版では、C++、Go、Java、JavaScript、Python、Rustの6言語から、Exercismの697問中で難しい225問だけを選び直しました。
当初は上位モデルが5%から50%程度に収まるよう難しくする狙いでしたが、aider leaderboardではGPT-5 highが88.0%、GPT-5 mediumが86.7%まで到達しています。
一方で、問題セットを置いているAider-AI/polyglot-benchmarkのコミットは2024年12月で止まっており、aider本体は更新されているものの、ベンチマーク自体が継続的に難しくなっているわけではなさそうです。
つまり、Exercism由来のベンチは難問に絞ってもいずれ上位が詰まり、更新を止めるとまた飽和に近づく、という流れがaider側でも起きています。
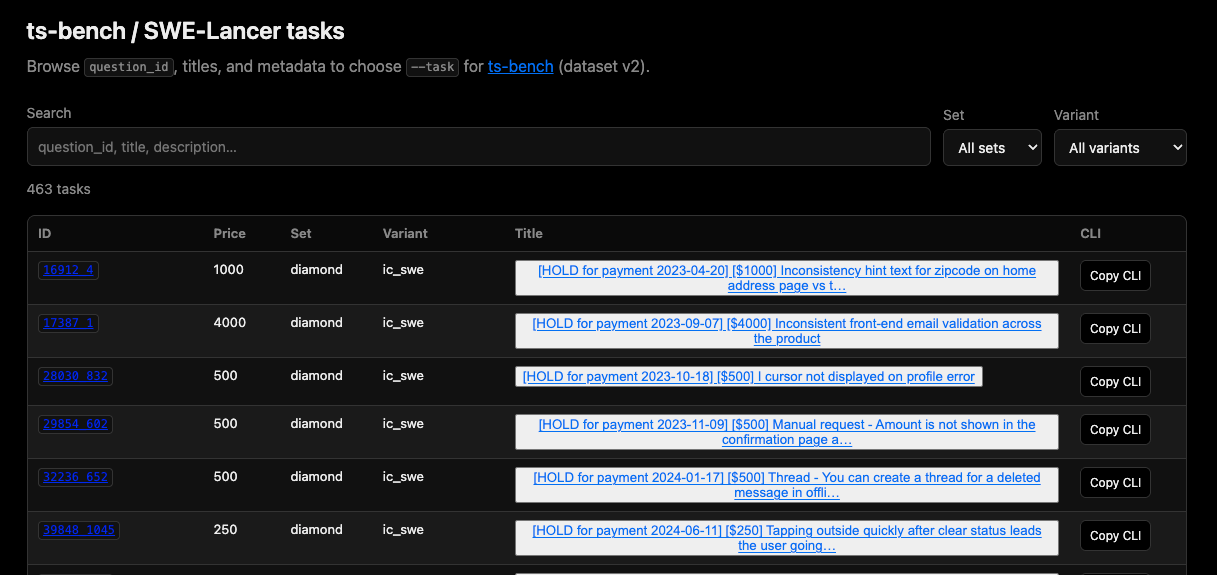
そこで、ts-benchで選んだのはOpenAIのSWE-Lancerです。
SWE-Lancer自体は以前から知っていて、「Kiroとコンテキストエンジニアリングの時流」でも触れたことがあります。
これはExpensify(React Native製の巨大アプリ)の実案件タスクを、報酬額つきで集めたデータセットです。
TypeScriptで書かれた巨大コードベースを対象にしていることも、v2の題材として選んだ大きな理由です。
論文上のSWE-Lancer全体は1,400件超、総報酬額は約100万ドルとされています。
一方で、現在公開リポジトリでオフライン実行用に検証されているIC SWE Diamondは198タスクです。
本記事で扱うts-bench v2は、このIC SWEタスクを主な対象にしています。
フロントエンド中心ではありますが、私たちが普段書いているコードに最も近い題材だと考えました。
実際のタスクは、アルゴリズム問題ではなく、アプリの細かいふるまいを直すものが多いです。
たとえばタスクの中には、郵便番号欄に , を入れてもエラーが出ない問題、絵文字リアクションボタンのサイズが仕様と違う問題、Markdownの見出しやコードブロックの表示が一瞬崩れる問題が入っています。
ほかにも、長い装飾付きメッセージを送ると文字数の数え方がずれてAPIリクエストが失敗する問題や、ミニメニューでコピーや未読化を押したあとにチャット入力欄へフォーカスが戻らない問題があります。
郵便番号、電話番号、入力検証、チャットUI、コピー操作、フォーカス、絵文字、Markdown表示のような、実際の業務アプリでよく見る種類の不具合です。
なおIC SWE Diamondの個々の報酬額には、$50や数百ドル規模のタスクも含まれます。
4月の標準セットとして選んだ5タスクは、報酬額が$2,000〜$8,000、合計$20,000のサブセットです。
報酬額は今回のベンチではスコアの計算には使っていません。
「報酬が高いタスクほど難しい」という、難易度の目安として利用しています。
実際に人手で値付けされた仕事なので、難易度のラベルとしては都合がよいのです。
どうやって測るのか
SWE-LancerはOpenAIの公式リポジトリでDockerイメージが用意されています。
ts-benchはそのイメージから環境を起動し、Pythonでブラウザ自動化テストを実行し、さらにmitmproxyで通信を再現して評価します。
これにより、筆者の手元だけに閉じない形で同じテストを回せます。
SWE-LancerのICタスクには、OpenAIの公式リポジトリに bug_reintroduce.patch が含まれています。
これは修正済みのコードにバグを再導入し、エージェントが解く開始状態を作るためのパッチです。
ts-benchのv2実行では、セットアップ時にこのパッチを当ててからエージェントを走らせ、最後に公式のpytestを実行します。
つまり、毎回のベンチ中に特別な正解検証を追加しているわけではありません。
標準セットを選ぶ段階では、セットアップやpytestが安定して動くタスクを選ぶようにしています。
ここはts-benchが一番こだわっているところです。
有名なベンチマークは、論文やリーダーボードの数字は立派でも、一般の開発者がそれを手元で即座に再現するとなると、環境構築だけで骨が折れます。
公開されているスコアが本当に自分の環境でも出るのか、それを確かめる手段が実質的にないことも多いのです。
ts-benchが目指すのは、自分のアカウントですぐ試せることです。
# https://laiso.github.io/ts-bench/auth/
bun src/index.ts --setup-auth codex
bun src/index.ts --dataset v2 --docker --tasks 14958,15815_1,15193,14268,20079 --agent codex --model gpt-5.5Dockerイメージから環境が立ち上がり、自分のAPIキーなりサブスクリプションなりで回せば、その場で同じ土俵のスコアが出ます。
GitHub Actionsにも載せてあるので、手元のマシンを長時間占有しなくてもベンチを回せます。
結果JSONやログ、実行手順も残るので、誰でも「自分の構成での数字」を自分の手で取れます。
2026年4月時点のスナップショット
この規模のテストを回すと、Max Planのサブスクリプションでもすぐ限界が来ます。
そこで4月は高難易度の5タスク(報酬合計$20,000、全タスク同一コミットに固定)だけを対象に、エージェントとモデルの組み合わせごとに一通り回してみました。
そのときに出たのが、5問の範囲では「Opusには解けず、Sonnetには解けた課題があった」という観測です。
値段の高いモデルが必ずしもすべてのタスクで強いわけではないのかもしれない。
繰り返しますが、これはあくまで4月のスナップショットなので、断定はしません。
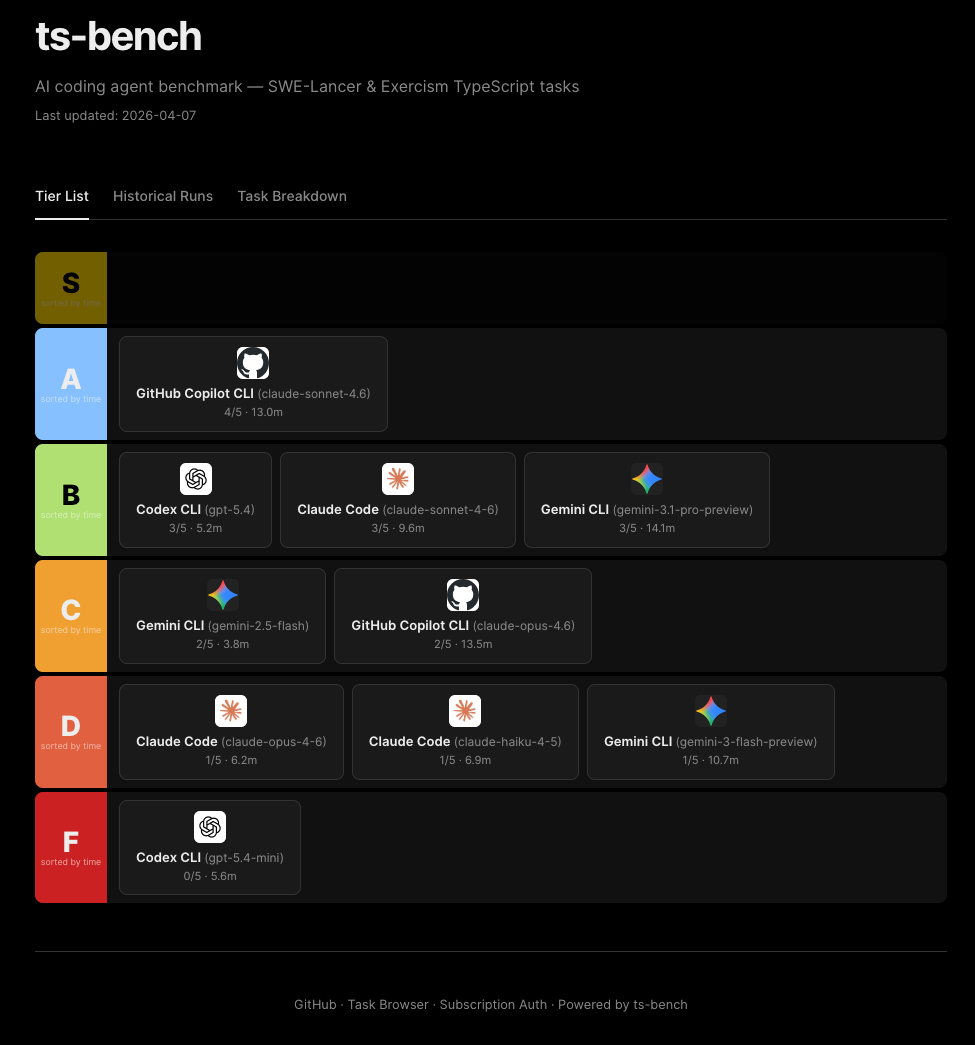
| Agent / Model | Tier | 解決 | 実行時間 |
|---|---|---|---|
| copilot / claude-sonnet-4.6 | A | 4/5 | 64.8分 |
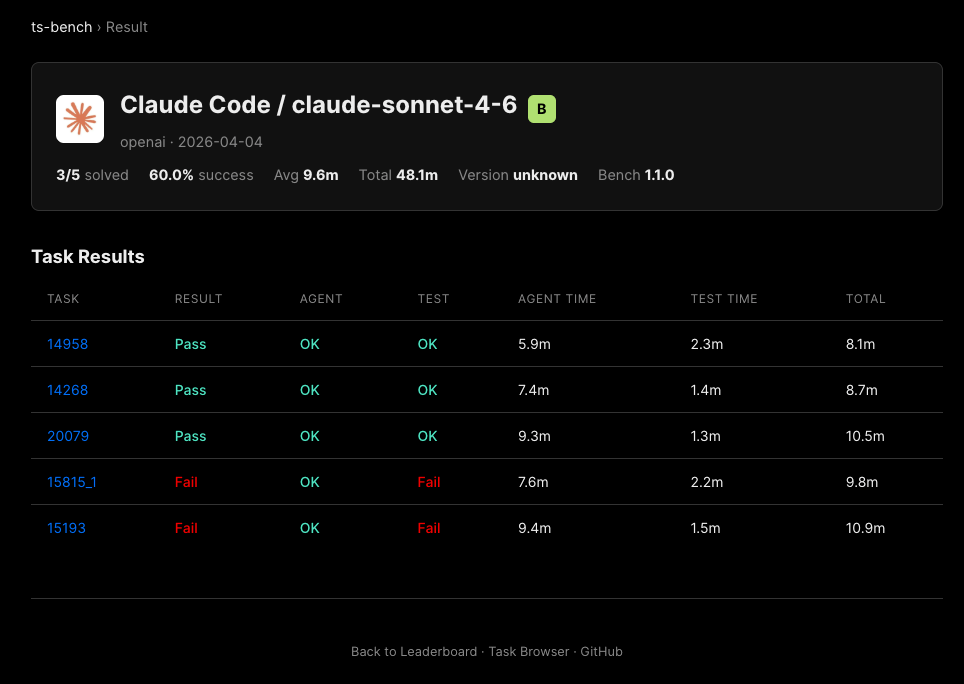
| claude / claude-sonnet-4-6 | B | 3/5 | 48.1分 |
| codex / gpt-5.4 | B | 3/5 | 26.2分 |
| gemini / gemini-3.1-pro-preview | B | 3/5 | 70.6分 |
| copilot / claude-opus-4.6 | C | 2/5 | 67.6分 |
| gemini / gemini-2.5-flash | C | 2/5 | 18.8分 |
| claude / claude-haiku-4-5 | D | 1/5 | 34.4分 |
| claude / claude-opus-4-6 | D | 1/5 | 31.2分 |
| gemini / gemini-3-flash-preview | D | 1/5 | 53.4分 |
| codex / gpt-5.4-mini | F | 0/5 | 28.1分 |
なぜランキングではなくティア分布なのか
エージェントとモデルの組み合わせを多数回すことを前提にすると、単純な1位2位ランキングはブレてしまって意味がありません。
だからある程度の母集団を確保したうえで、結果をティアで束ねて分布として見せたいと考えています。
そもそもts-benchが測りたいのは、最高性能の競争ではありません。
「このモデルがあのモデルを何点上回った」という競争は、潤沢な予算と大規模な計算資源を持つ企業に任せておけばよく、個人が知りたいのはむしろベースライン、いわば足切りのほうです。
このエージェントとこのモデルを組み合わせたら、だいたいどのくらいの性能水準が見込めそうか。
実用に足りるのか、それとも全然動かないのか。
そのあたりをつけることが個人でも自分の手でできる、というのがティアで束ねる狙いです。
この考え方は、後述するCursorBenchの設計にも近いものがあります。
CursorBenchも、リーダーボードの順位そのものより、モデル間の差が実作業で見えるような評価セットを作ることを重視しています。
筆者も同じく、細かな順位より「この組み合わせは実用圏にいるのか」を見たいのです。
ところが、ここに予算の壁があります。
理想は5タスクではなく、公開リポジトリで検証済みのIC SWE Diamond 198タスクを各層で回すことですが、これは現実的にコストが足りません。
今回この記事を書いたきっかけのひとつが、この「やりたい計測と予算のギャップ」です。
サブスクリプションで計測コストを下げる
v2にあたって、これまでAPIの従量課金でしか測れなかったところを、サブスクリプションの認証情報でも計測できるようにしました。
APIキーで大規模に回すと、タスク数とモデル数に比例して従量課金が積み上がります。
個人が継続的に198タスク規模へ広げるには、このコストがかなり重くなります。
そこで、すでに契約しているClaude Code、Codex CLI、Copilot CLIなどのサブスクリプションに相乗りして計測できるようにしました。
これでだいぶ安くなりましたが、それでも母集団を増やすにはまだ限界があります。
エージェントが読むドキュメントを整える
リポジトリ内のドキュメントは基本的に「エージェントが読む」前提で整備しています。
実際に見ると、AGENTS.md は長い説明ではなく、「bunを使う」「v2はDockerが必要」「setup-v2-envを先に実行する」といった作業上の制約だけを短く置いています。
詳細は specs/000-project-handbook/ に分け、環境、サブスクリプション認証、GitHub Actions、エージェント追加、並列実行、トークン集計を別ファイルに置いています。
たとえば adding-agents.md では、新しいエージェントを足す場所を src/agents/registry.ts と scripts/agents.json の2つに絞り、型定義やヘルプ表示は自動で派生すると明記しています。environment.md では、v2のGitHub Actionsの入力、必要なシークレット、成果物、ログの場所、タイムアウトの伸ばし方まで書いてあり、失敗したときにエージェントが次に見るべき場所を迷いにくくしています。
つまりドキュメントは読み物というより、エージェントが作業中に参照する運用メモとして設計しています。
モデルの性能向上でベンチマークも変わってきた
モデルやエージェントの性能が上がるにつれて、ベンチマークの設計、目的、質も変わってきました。
公開ベンチマークが飽和してきたという感覚は、筆者やv1のユーザーだけのものではありません。
OpenAIは2026年2月に、SWE-bench Verifiedの結果を報告するのをやめました。
最先端モデルが正解パッチを記憶から再現できてしまい、未解決問題の6割近くにテストの不備が見つかったからです(OpenAIの説明)。
この流れは、2025年後半以降に出てきた新しいベンチマークにも表れています。
SWE-bench Proは、長期的なソフトウェアエンジニアリングタスクを対象にし、公開セットと商用セットの結果が広く参照されるようになりました。
論文では、曖昧なIssueに必要な説明を足し、テストを採点に使えるようにするために、人間が3段階で内容を見直したと説明されています。
DeepSWEも注目されているベンチマークです。
DeepSWEは、アクティブなオープンソースリポジトリから作った113件の長期的なソフトウェアエンジニアリングタスクで、TypeScript、Go、Python、JavaScript、Rustを含みます。
各タスクは隔離された実行環境とテストプログラムを持ち、参照解は採点時には使わず、ふるまいが正しければ通す設計です。
参照解は採点のためではなく、レビュー時にタスクが妥当かを確認する材料として置かれています。
Terminal-Bench 2.0も同じ時期の重要な流れです。
これはコード修正だけでなく、ターミナル環境でのセットアップ、実行、検証までをひと続きの作業として測ります。
論文では、89件のタスクが3人の人間レビュアーによって正しさを確認されたと説明されています。
採点自体はテストスクリプトで自動化しつつ、タスクの妥当性は人間が見る形です。
さらにTerminal-Benchの作り手は、Harborという評価フレームワークも整備しています。
Harborは、任意のエージェント、タスク環境、サンドボックス、実行結果を共通の形式で扱うための基盤です。
このように、タスクだけでなく実行と共有のためのフレームワークを作る動きも重要になっています。
SWE Atlasは、Issue解決だけではなく、コードベースQ&A、テスト作成、リファクタリングを分けて測ります。
たとえばコードベースQ&Aでは、あらかじめ用意した採点基準ごとに回答を採点します。
リファクタリングでは、テストが通るかだけでは保守性や設計の改善を測りにくいので、変更差分を採点基準に照らして見ます。
SWE Atlasの説明では、この採点にClaude Opus 4.5を使っています。
つまり、人間が見るポイントを先に決めて、それを自動採点に寄せていく方向です。
SWE-EVOは、DjangoやNumPyなどの実プロジェクト履歴をもとに、要求仕様に沿ってコードベースを継続的に進化させる長期タスクを扱います。
単発のバグ修正だけでは実用上の能力を測りきれない、という問題意識は共通しています。
ここで難しいのは、実務に近づけるほど、人間の判断がどこかに入ることです。
Issueの説明が十分か、テストが厳しすぎないか、別解を許せるか、リファクタリングの品質をどう見るか。
これらは完全に共通化しにくいので、各ベンチマークは、人間がタスクや採点基準を作り、実行時の採点はできるだけプログラムや明文化した基準に寄せる、という形で工夫しています。
ts-bench v2も、これらの新しいベンチマークと同じ方向を向いています。
つまり、短い競技問題ではなく、実リポジトリ、長い実行時間、環境構築、テスト、エージェント製品ごとの差を含めて見る方向です。
違いは、ts-benchはTypeScript製の巨大アプリと、個人が普段使うエージェント製品の組み合わせに寄せている点です。
採点はまず自動テストに寄せつつ、どのタスクを標準セットに入れるかは、人間が実用上の妥当性を見て選んでいます。
同じ問題意識は、企業が自分たちの実作業から独自ベンチを作る動きにも出ています。
企業も実作業から独自ベンチを作っている
CursorはCursorBenchを作っています。
これは「Cursor Blame」でコミット済みコードを生成元のエージェント要求まで遡り、開発者の指示と正解コードの対を自動で集めたものです。
多くは自社コードベースから取るので、学習データに混入する汚染のリスクが小さくなります。
タスク記述はGitHub Issueのように詳細ではなく、実際に開発者がエージェントに話しかけるときの短く曖昧な形に寄せてあり、数か月ごとに作り直しているそうです。
Clineのcline-benchは、実際のコーディングセッションでモデルが手動介入を要したり完遂できなかったりしたタスクを候補にします。
公開される各タスクは、開始スナップショット(オープンソースリポジトリのgit commit hash)、開始プロンプト、そして実際にコミットされた最終状態をもとにしたテストで構成されます。
Clineの記事でも、各タスクをHarbor(Terminal-Bench 2.0)やPrime Intellect Environments Hubのような仕様に沿った再現可能な環境としてパッケージする、と説明されています。
こちらは検証や再現を誰でもできるように、オープンソースのリポジトリだけを対象にしています。
共通しているのは、合成的なパズルではなく自分たちの実際のコミットやPRからタスクを作る、という発想です。
ts-benchが個人の規模でやろうとしていることと、根っこは同じだと思っています。
前述のとおり、ts-benchはこの「実作業からベンチを作る」部分を自分のプロジェクトに引き寄せて使えます。
国内でも近い取り組みがあります。
逆瀬川ちゃん(@gyakuse)さんは、HarnessBenchというCoding Agent比較用のベンチマークを公開しています。
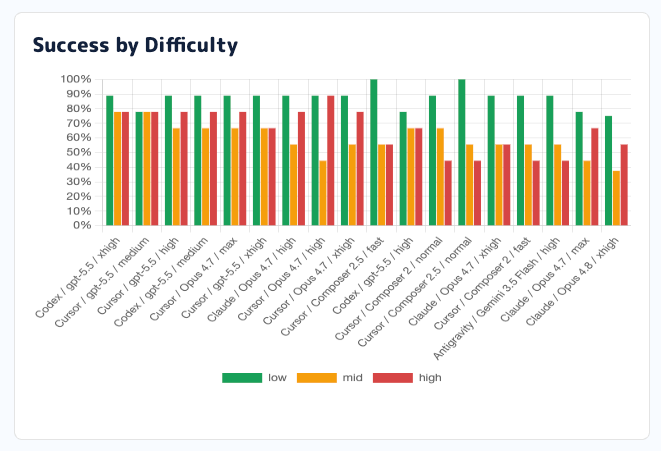
9個の実OSSリポジトリからlow、mid、highの3問ずつ、合計27問を作り、Codex CLI、Claude Code、Cursor Agentなどの商用CLIハーネスを同じ問題で比較しています。
採点では、LLMによる主観的な判定を主役にしていません。
最近のPull Requestを起点に問題を作り、エージェントには見えない非公開テストで結果を判定します。
そのテストは、バグが直ったかを見るメインのテストと、周辺機能を壊していないかを見る回帰テストに分かれています。
また、AGENTS.mdやCLAUDE.md、.codex、.claude のようなリポジトリ内の指示ファイルを無効化して、ハーネスごとの事前知識や誘導が混ざりすぎないようにしています。
これはts-benchの問題意識とかなり近いです。
モデル名だけでなく、Codex CLI、Claude Code、Cursor Agentのようなハーネス込みで測り、PR由来の実タスクを使い、採点はできるだけテストに寄せる。
さらに27問なので小さな差を断定しない。
このあたりは、個人や小規模チームが現実的に作れるエージェント評価として参考になります。
自分でカスタマイズして使うユーザーたち
ありがたいことに、ts-benchを自分の環境に合わせてカスタマイズして使うユーザーがすでに出てきています。
中でも目立つのが金のニワトリ(@gosrum)さんで、RTX 5090やM2 Ultraの手元環境で、Qwen3.5やGLM-5、Gemma 4、Kimi-K2.5といったローカルLLMを次々とts-benchで測って公開しています。
コーディングエージェントのベンチマーク(ts-bench)結果を可視化するアプリを実装した
— 金のニワトリ (@gosrum) March 30, 2026
従来のタスク遂行率だけでなく、
・Tool callの回数
・エラー発生率
・トータルトークン数
も一気に見れるので、モデルの「Tool Callのうまさ」と「コスパ」も評価できる
ちなみに画像では、Claude Code +… https://t.co/HbCPz7Bfnt pic.twitter.com/p8ai740YIa
面白いのは、その使われ方がまさに「エージェントハーネスとモデルの組み合わせ比較」になっていることです。
同じローカルLLMでも Claude Code と opencode と vibe-local でスコアや速度が変わる(「Macならvibe-localの方が倍以上速い」など)という知見が、実測で次々に出てきています。
kimi-cliを動かせるようts-benchを改修したり、タスク遂行率だけでなくTool callの回数やエラー率、総トークン数を見る可視化アプリを自作したりと、ベンチのカスタマイズも進んでいます。
これはまさにts-benchが目指していた使われ方です。
SWE-Lancer本家はOpenAIが用意した評価コードと実行方法で動きますが、ts-benchは評価ハーネスの中で呼び出すエージェント部分を差し替えます。
これにより、自分が使うエージェントとモデルの組み合わせを測れるようにしてあります。
前述のとおり、環境はDockerイメージから再現できるので、各自の手元で「自分の構成」を測れるわけです。
差し替えられるのはエージェント部分だけではありません。
データセットそのものを自分のプロジェクトに置き換えることもできます。
評価対象のリポジトリ、テスト用のDockerfile、タスクの一覧をまとめたCSV(自分たちのチケットをCSVに書き出したもの)を用意すれば、SWE-Lancerの代わりに自分たちのコードベースを題材にした評価ハーネスが組めます。
ts-benchは、OpenAIやCursorの社内ベンチのように、そうした「自社向けの評価基盤」を作るときのベースとしても使えるわけです。
おわりに:スポンサー募集
ts-benchはまだ結論の出ていない継続プロジェクトです。
母集団を増やして分布の精度を上げ、新しいモデルが出るたびに自分のエージェントハーネスと組み合わせて測り続けたいと考えています。
ここまで説明してきたとおり、ts-bench v2は実在のモノレポと最先端モデルと複数のエージェントを回すため、計測のたびにAPIや計算のコストが積み上がります。
しかも本当に欲しいのは「一回のスナップショット」ではなく、ティア分布として意味のある母集団です。
分布を出すには回数を重ねる必要があり、回数を重ねるには予算が要る。
とてもシンプルな話です。
そこで、月次でリーダーボードを更新し続けるための運用を支えてくださるスポンサーを募集しています。
いただいた支援は、そのまま計測の母集団を増やす費用になります。
具体的には以下のような未解決タスクに使う予定です。
- タスクやエージェントごとのDockerとmonolithのセットアップ費の削減(一度のsetupで複数エージェントを切り替える)
- Docker monolith からネイティブVMプロビジョニングへの移行(Docker-in-Dockerの排除)
- IC SWE Diamond 198タスクへの段階的な拡大
支援の入り口は2つあります。
目的はあくまでこのプロジェクトによって「使えるデータとその枠組みを作ること」で、支援はそれをもっと量も頻度も厚くするためのものです。
