TypeScriptファーストなコーディングAIエージェントのベンチマーク「ts-bench」を公開しました
AIコーディングエージェントのTypeScriptコード編集能力を評価するための、手軽に再現可能なベンチマークプロジェクト「ts-bench」を公開しました。この記事では、筆者がなぜ ts-bench を作ったのか、今後どうしていきたいかについてお話しします。
ts-benchの仕組み
ts-benchは、プログラミング学習プラットフォーム Exercism のTypeScript問題セットを利用します。各問題には、仕様を説明するドキュメント、エージェントが編集すべきソースコードのひな形、そして正解判定に使うテストコードが含まれています。
ベンチマークタスクは、各問題に対して以下の4つのステップを順番に実行します。
- AIエージェントの実行: 問題の指示書をプロンプトとしてAIエージェントに渡し、ソースコードを編集させます。
- テストファイルの復元: エージェントが誤ってテストコードを書き換えてしまう可能性を排除するため、テストファイルを実行前に元の状態へ復元します。
- テストの実行と評価: 最後に、yarn test コマンドを実行し、すべてのテストが通れば「成功」と判定します。
この一連のプロセスを通じて、各エージェントがどれだけ正確にタスクをこなせるかの成否と時間を測定しています。
ts-benchは、エージェントが内部で複数回の試行錯誤(コード編集とテスト実行の繰り返し)を行うことを許容しており、最終的に提出されたコードがテストをパスできるかを評価します。これは、一度の回答で正解を目指す pass@1 のような単純な指標とは異なり、より実用的な開発プロセスに近い形でエージェントの能力を測定することを目指しています。
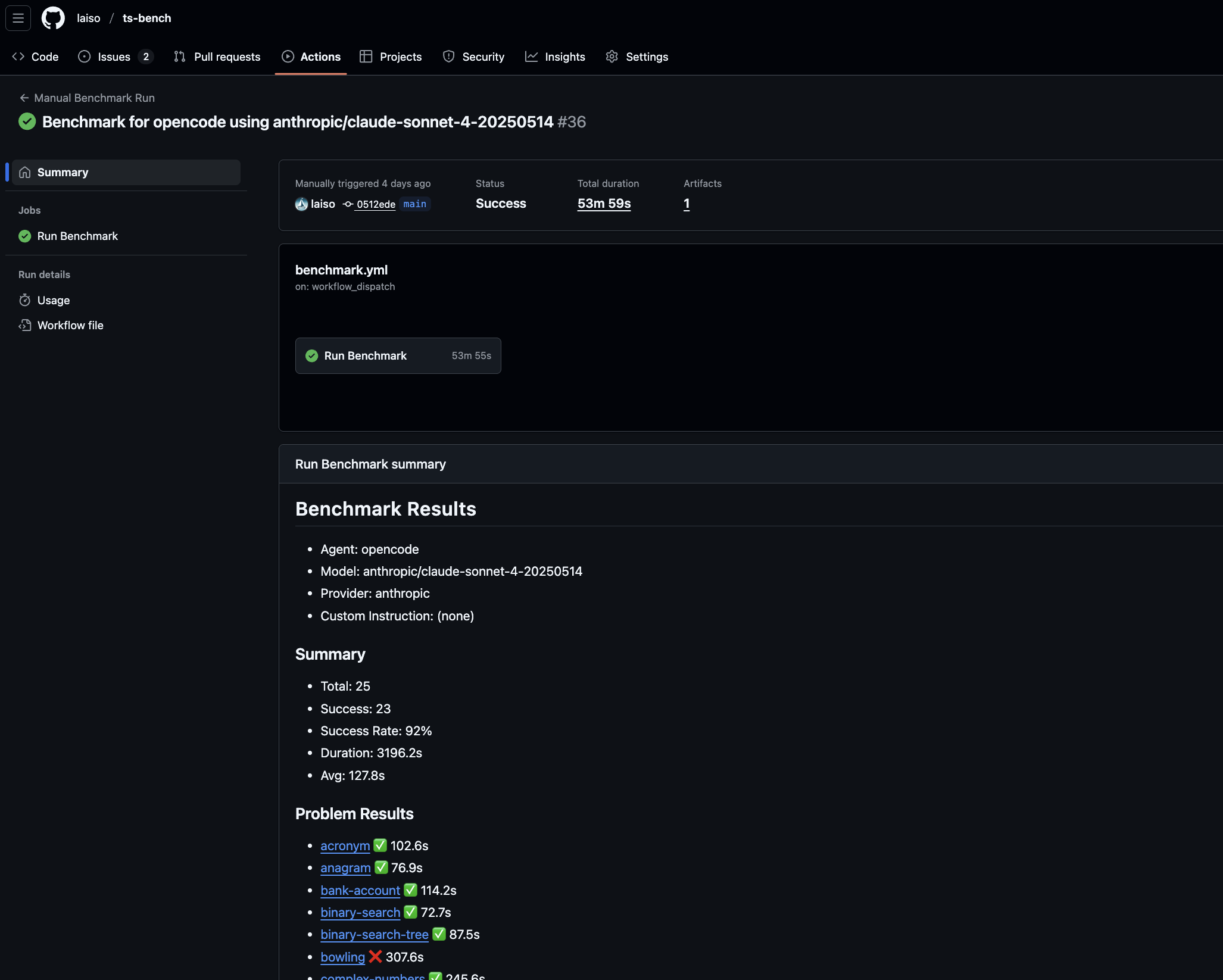
すべてのベンチマーク結果はGitHub Actions上で実行され、結果はGitHubのワークフロー画面から確認できます。これを見ることでエージェントがどの過程で失敗したのか分析できます。
なぜTypeScriptなのか?
既存の多くのベンチマークは、Pythonを用いたアルゴリズム問題のコード生成能力を測定することに焦点を当てています。しかし、実際の開発現場、特にフロントエンドやNode.jsを用いたモダンな開発では、バックエンドにどんな技術を選ぶかに関わらず、TypeScriptはほぼ必ずと言っていいほど登場する技術だと思います。
現在のAIコーディングエージェントは、自身が生成したコードに起因するビルドエラー、そしてテストの失敗をうまく解決できず、修正を試みては失敗するという無限ループに陥ってしまうことが少なくありません。これは、単にコードを一度生成して終わりではなく、型チェッカー、ビルドツール、テストランナーといった厳格なフィードバックシステムにどう対応できるかという、より実践的な能力が問われる場面です。
このプロセスで本当に重要になるのは、コードそのものを一度で完璧に生成する能力以上に、要件を実現するためにフィードバックループを正確に回す能力です。ts-benchは、まさにこの点を評価するためにTypeScriptをベンチマークの対象としています。静的型付けがもたらす特有の課題をエージェントがどう解決していくかを観察することで、より実践的な開発能力を測定することを目指しています。
ts-bench を作った理由
AIコーディングエージェントの進化は目覚ましく、多くのツールが日々登場しています。しかし、その性能を客観的かつ効率的に評価するのは簡単ではありません。ベンダーの発表するSWE-bench Verifiedのスコアも半ばプレスリリース駆動の指標になっており、我々がコーディングエージェントからモデルを利用する際の参考にならなくなっています。そこで、筆者は、特に以下の課題を解決するために ts-bench を開発しました。
1. コーディングエージェントの効率的な評価と足切り
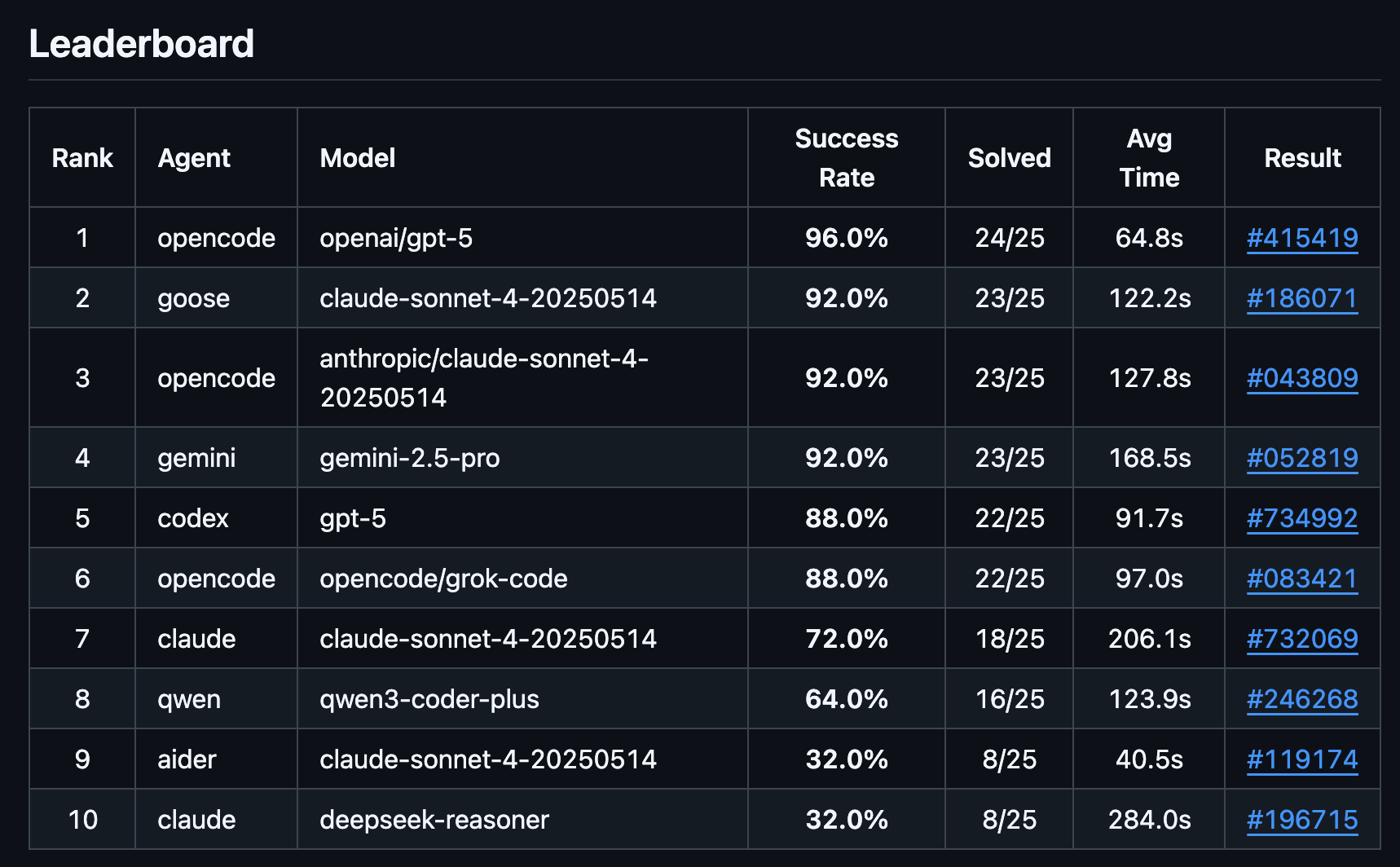
実用的な開発タスクを任せるには、エージェントが一定の品質基準を満たしているかを見極める必要があります。ts-bench の枠組みを使えば、基本的なコーディング能力を持たないエージェント環境を効率的に足切りできます。実際に、ベンチマークを実行したところ「Claude Code と DeepSeek V3.1モデル」の組み合わせが低いスコア(正解率32.0%)を記録するなど、特定の組み合わせにおける性能の課題が明らかになりました。
このベンチマークで自動化して検証できるのはCLI型でコマンド実行できるエージェントに限りますが、同じ問題を使えばエディタ型やウェブサービスとして実行する完全自律型エージェントでも手動操作によってどの程度難問タスクが解けるのかは明らかにできます。以下の記事では同じデータセットを使いDevinやJulesなどにタスクを解かせた結果を記載しています。
このように日々アップデートされるコーディングエージェントの情報から実際の性能評価を同じ基準で実施して、選別できるようにしています。
2. エージェントとモデルの多様な組み合わせパターンの検証
本プロジェクトは、LLM単体の性能ではなく、プロンプト戦略やコマンド実行・ファイル操作のロジックまで含めた「エージェント層」全体を評価することに重点を置いています。
例えば、opencode のようなエージェントが、様々なモデルと組み合わされた際にどのようなパフォーマンスを発揮するのかを、他の条件を揃えて比較できます。リーダーボードを見ても、opencode が複数のモデルで上位にランクインしており、その有効性が分かります。現在はClaude CodeとSonnet 4の組み合わせよりも高い成功率を出せているのが興味深いですね。
3. 特定バージョンにおける問題の再現と実証
以前に話題になった「Claude Codeがアホになる問題」のように、エージェントはバージョンやプロンプトの変更によって性能が大きく変わることがあります。ts-bench では、特定の条件下でのスコアの変化を実証し、性能の変遷を追跡することが可能です(バージョン切り替えは現在インストールスクリプト書き換えが必要です)。実際に、最新版のClaude Codeでは、より詳細な指示をプロンプトに含めないと正しく機能しないケースも確認できました。
- Claude Code v1.0.98(その時点での最新)ではSuccess Rate: 64%、Avg: 184.2sを記録
- Claude Code v1.0.24ではSuccess Rate: 80%、Avg: 130.7sに改善
- Claude Code v1.0.102(その時点での最新)でテスト実行ステップ詳細をプロンプトに含めることでv1.0.24同等まで回復
4. 自作エージェントの評価基盤としての利用
筆者はエージェントの内部構造を解析しているうちに、自作エージェントの開発に興味を持ちました。筆者以外にも、独自に開発したエージェントの性能を客観的に評価したいというニーズがあると考えています。ts-bench は、そのような開発者が改善点を見つけるための基盤としても機能すると考えています。
公開の影響とコミュニティからの反響
ts-bench は、再現性を重視して設計されています。Docker と GitHub Actions を活用することで、誰でも同じ環境でベンチマークを実行できます。この取り組みのおかげで、Xのフォロワーに先行して公開した後、すぐに多くの方に利用していただくことができました。
特に、GPT-OSS のようなローカルLLMの性能評価に活用されるなど、コミュニティベースでの利用が広がっています。Aider ベンチマークのような既存の評価セットよりも手軽に試せる点が、功を奏したのかもしれません。
laisoさんのts-benchが気になったので、codexでローカルLLMの評価をできるようにしました。そして、いくつかのモデルで評価してみました。
— 金のニワトリ (@gosrum) August 31, 2025
その結果、なんとcodex + gpt-oss:120bがclaude code + Claude Sonnet 4と同スコアになりました!
※一度きりの評価なので、多少ブレはあると思います https://t.co/dM54yPfTwJ pic.twitter.com/sRngPTE5zJ
ts-bench のこれから
現在の ts-bench は、ベースライン性能の測定には非常に有効ですが、フロンティアモデルにとっては問題が簡単すぎるという課題も認識しています。今後は、トップラインの性能も測定できるよう、より挑戦的なタスクをデータセットに組み込んでいきたいと考えています。具体的には、TypeScript を用いた大規模なリポジトリ編集能力を測れる「SWE-Lancer」のようなデータセットの活用を検討しています。
一方で、このような有料のAPI呼び出しを大量に行うベンチマークの実行にはコストがかかるという現実的な問題もあります。著者は米テクノロジー業界の著名人であるAider の作者のように潤沢な資金があるわけではない市民開発者であるため、現在は効果測定ができる最小限のセットで運用しています。たとえばCursor CLIやSonnetの7倍のコストが予想されるOpusではまだベンチマークを実施できていません。今後は、スポンサーを募るなど、少しずつプロジェクトを拡張していく方法を模索していきたいと考えています。興味のある方は以下のリンクからぜひご検討ください。
おわりに
ts-bench は、AIコーディングエージェントの進化を客観的な指標で後押しするためのプロジェクトです。ぜひ GitHub リポジトリをご覧いただき、フィードバックやコントリビューションをいただけると嬉しいです。