Serena MCPはClaude Codeを救うのか?
「Claude Codeがアホになる問題」が勃発している最中、SerenaというMCPサーバーが「Claude Codeのコンテキスト消費を削減し、応答を改善する」という評価でユーザーたちの間で注目されています。
筆者も実際にSerenaを使ってみたところ、確かにコンテキスト効率の改善(入出力トークンの減少を指します)を実感できました。詳しく調べてみると、このツールは非常にユニークな発想で設計されており、一過性の流行として消費されるには惜しいと感じました。
そこで、本記事では、この機能の背景にある技術的な仕組みを詳しく解説したいと思います。実際の検証も交えながら、Serenaのアーキテクチャとその効果を分析していきます。
現在のコーディングエージェントが抱える課題
現在のコーディングエージェントの多くは、コードを単なるテキストファイルとして扱って逐次的な処理をしています。この根本的なアプローチが、制約を生み出しています。
大規模なプロジェクトで作業する際、エージェントは必要な情報を見つけるために膨大なテキストを読み込まなければなりません。関数の定義を探すだけでも、リポジトリをfindやgrepして、ヒットしたファイルを読み込み、多段階の正規表現やキーワードマッチングに頼って探索する段階をたどらざるを得ません。 これは人間の開発者がIDEで「関数定義へ移動」を一瞬で実行できるのとは距離があります。
大きなファイルは数百行ずつバッファリングして処理するため、コード全体の構造を把握することが困難です。大規模プロジェクトになるほどこの問題は深刻化し、処理時間の増大とトークン効率の悪化を招きます。
このコードベースの探索・読み込みの問題は、すでに一部のAIエディタで導入されているRAG(Retrieval-Augmented Generation)ベースのAgenticなアプローチを導入したとしても発生します。現在のRAGの精度ではエージェントは検索で適切な参照を見つけられずに関連コードを見逃したり、逆に不要な情報まで含めてコンテキストを膨張させてしまいます。Claude Code開発チームを初期にRAG方式のコード検索を実装し、比較した上で現在のコマンドベースのコード検索に移行した経緯があります。
書き込み処理においても、現在のエージェントは低レベルなツールに依存しています。
エージェントはAPIのFunction Callingで受け取った「置き換え元」と「置き換え後」のテキストペアをNode.jsのfsモジュールなどの標準的なFile I/Oメソッドでファイルに適用します。編集は常にファイル単位で行われ、まず置き換え元のテキストを指定されたパスで検索し一致させ、置き換え後のテキストに展開するという基本原理になります。
これらアプローチの最も重要な問題は、意味的な理解の欠如です。いわゆる「名前重要[1]」です([1]:名前重要 | プログラマが知るべき97のこと)。AIは関数やクラスといったシンボルレベルでの認識や操作ができず、定義と参照の関係を理解した上での編集ができません。リファクタリングや定義ジャンプなど、開発者が日常的に使うIDEの機能をAIは利用できず、各プログラミング言語の特性を考慮した処理もできません。
これらの制約により、現在のコーディングエージェントは、単純なテキスト編集でできる範囲に自動化が留まっているのが現状です。
Serenaの登場
Serenaは、AIエージェント向けのコーディング支援ツールです。MCPサーバーとして任意のアプリから呼び出します。 テキストベースのファイル操作の代わりに、LSP(Language Server Protocol)を使ってシンボルベースでコードの解析・編集を行います。 Oraios AI(ドイツの会社)が2025年4月ごろにGitHubで公開したプロジェクトです。創業者二人がコードを書いており、オープンソースとして公開されています。
SerenaはフロントエンドのUIを持たない、バックエンド専用のMCP(Model Context Protocol)サーバーとして動作します。 MCPのToolを通じてLSPベースのコード解析・編集機能をAIエージェントに提供します。 これによって、エージェントはIDEが内部的に使用しているような参照・編集機能を呼び出せるようになります。
このMCPサーバーをClaude DesktopやClaude Code、VS Code、Cursor、IntelliJなどのMCPホストアプリケーションから接続して利用できます。 特にClaude Desktopで使用する場合は、Claude Codeのclaude mcp serveでバックエンドのみ使うアプローチに近い構成となります。
Serenaの作者の一人であるMichael Panchenkoは、前節で説明したような従来のコード参照・編集のアプローチが抱える課題を解決する形で、SerenaのアイデアであるLanguage Server Protocol (LSP)の統合を行ったことをRedditの投稿で述べています。
私たちはMCPサーバーを言語サーバーおよび シンボル検索・編集操作と統合しました。これにより、ClineのRAGシステムなどを置き換えています。この統合作業が最も時間を要した部分であり、この機能こそがSerenaを真に実用的で強力なAIエージェントとして機能させる鍵となっています。言語サーバーがなければ、単なるMCPシステムに過ぎなかったでしょう。
https://www.reddit.com/r/ClaudeAI/comments/1jpavtm/comment/mky441o/
対応言語
Serenaのプログラミング言語は、以下の三段階に分けられます。
現在サポートしている言語:
- Python、TypeScript/JavaScript、Go、Rust、C#、Java、PHP、Elixir、C/C++、Clojure
サポートしているがテストされていない言語:
- Ruby、Kotlin、Dart
未対応の言語の例:
- Swift、Scala、Erlang、Haskell、R、Julia、Perl、Lua、Groovy、Scala、Erlang、Haskell
Serenaが個別に対応したLSPごとに利用可能なため、対応言語はSerena内のプロバイダー実装の有無に依存します。たとえばSwiftはメジャーな言語ですが、開発チームがMacを使用していないため対応できておらず保留中とのことです。
Serenaの利用方法
SerenaのMCPサーバーを単体で起動するには、以下のコマンドを実行します。これはGitHubからチェックアウトしたPythonパッケージをダイレクトに実行するコマンドです。 --projectで現在のディレクトリを指定することで、Serenaがアクセスできるパスを制限します。
uvx --from git+https://github.com/oraios/serena serena-mcp-server --project $(pwd)
このコマンドを実行すると自動でSerenaのWebダッシュボードページがブラウザで開き、ログが閲覧できます。このページを毎回見たくない場合は--enable-web-dashboard falseで抑制します。
Claude CodeからSerenaを利用するには、MCP設定でこのserena-mcp-serverの起動コマンドを記述します。ドキュメントによると以下のコマンドです。
claude mcp add serena-mcp-server "uvx --from git+https://github.com/oraios/serena serena-mcp-server --context ide-assistant --project $(pwd)"
コンテキストオプションの使い分け
Serenaは起動時の--contextオプションで有効にするToolセットを切り替えられます。使用するMCPホストアプリケーションに応じて適切なコンテキストを選択してください。
# Claude Desktop向け(デフォルト)
uvx --from git+https://github.com/oraios/serena serena-mcp-server --context desktop-app
# IDE向け
uvx --from git+https://github.com/oraios/serena serena-mcp-server --context ide-assistant --project $(pwd)
# エージェントフレームワーク向け(現在Angoのみ)
uvx --from git+https://github.com/oraios/serena serena-mcp-server --context agent
IDE向けのide-assistantコンテキストでは、以下のToolが除外されます:
>INFO 2025-08-01 16:02:16,171 [MainThread] serena.config.serena_config:apply:108 - SerenaAgentContext[name='ide-assistant'] excluded 9 tools: create_text_file, read_file, delete_lines, replace_lines, insert_at_line, execute_shell_command, prepare_for_new_conversation, summarize_changes, get_current_config
Claude DesktopからこのMCPサーバーを使って開発したい人は--context ide-assistantをつけずにデフォルトのdesktop-appを使ってください。
Docker経由での起動
筆者はローカルPCで直接起動せずにDockerで起動するよう設定しました。検証のために特定のプロジェクト以下をコンテナ内で動作され、Claude Codeの設定もプロジェクトローカルにします。
お持ち帰り用のワンライナーが以下になります。.mcp.jsonに設定が保存されます。
claude mcp add -s project serena -- docker \
run \
--rm \
-i \
--network host \
-v "$(pwd):/workspaces/projects" \
ghcr.io/oraios/serena:latest \
serena \
start-mcp-server \
--transport stdio \
--context ide-assistant \
--project /workspaces/projects
claude mcp list
Checking MCP server health...
# serena:.. ✓ Connected と出れば起動成功
SerenaのMCPツール
Serenaは起動時のコンテキストに応じて様々なMCPツールを提供します。ide-assistantコンテキストでは22個のToolが有効になります:
INFO 2025-08-01 16:02:16,179 [MainThread] serena.agent:_update_active_tools:362 - Active tools (22): check_onboarding_performed, delete_memory, find_file, find_referencing_symbols, find_symbol, get_symbols_overview, insert_after_symbol, insert_before_symbol, list_dir, list_memories, onboarding, read_memory, remove_project, replace_regex, replace_symbol_body, restart_language_server, search_for_pattern, switch_modes, think_about_collected_information, think_about_task_adherence, think_about_whether_you_are_done, write_memory
私たちの目的はおもにsymbol関連のLSPを利用したToolです。しかし、それ以外にもさまざまなToolが追加されます。
read_memoryやwrite_memoryはメモリ管理という別の機能のためのToolです。.serena/memories/ディレクトリにはメモリ管理のためのMarkdownファイルが自動で保存されます。ClineでいうMemory Bank、KiroでいうSteeringです。Claude Codeでは CLAUDE.mdがこの役割を包括していますね。なので設定ファイルで外すこともできます。
Serenaでプロジェクトが初めて有効化される際に.serena/project.ymlファイルが自動生成されます。excluded_tools設定でプロジェクトごとに特定のツールを除外できます。
Serenaによるコンテキスト削減効果の測定
Claude Codeを起動します。今回はSerena自身のリポジトリを実験台に使いました。Pythonを中心に約3万行のソースコードがあります。SerenaのMCP Toolによってコンテキストの変化を観察するために--verboseオプションをつけて起動します。
claude --verbose
架空のIssueをでっち上げて何か探索作業をしてもらいましょう。以下が指示となる文章です。
Language Server(LS)インストール時の問題を修正する
### 問題点
- **不要なインストールが発生する**
既にインストール済みのLanguage Serverが毎回再インストールされてしまい、ビルド時間やストレージを無駄に消費しています。
- **Clojure用Language Serverのインストールパスが不適切**
ClojureのLSがユーザーホームディレクトリ以外のパスにインストールされており、パーミッションや環境差異による問題が発生する場合があります。
- **Elixir Language Serverの構造が他と一貫していない**
Elixir LSのインストールや管理方法が他のLSと異なり、メンテナンス性や拡張性が低下しています。
これを送信するとClaude CodeはTaskツールで以下の計画を立てました。
⏺ Update Todos
⎿ ☐ Language Serverのインストール処理を調査し、現在の問題点を特定する
☐ Clojure Language Serverのインストールパスを修正する
☐ 重複インストールを防ぐ機能の改善
☐ 修正後のテストを実行し、フォーマット・型チェックを行う
早速Claude Codeがget_symbols_overviewというToolを呼び出してくれました。このToolは、ファイルやディレクトリ内のクラスや関数の一覧を取得するものです。
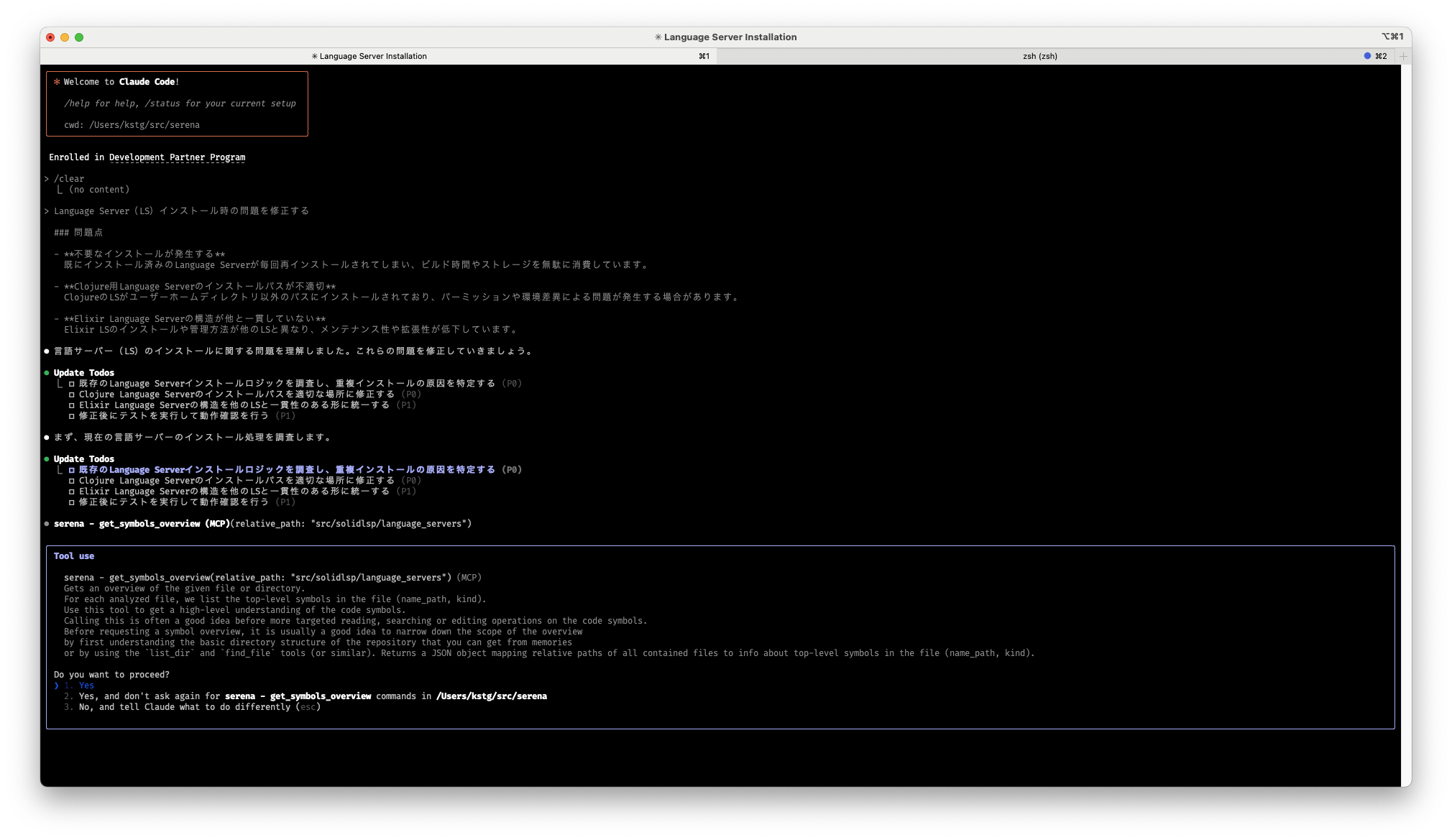
しかし、最初の呼び出しはエラーで失敗します。すると自動的にcheck_onboarding_performedという初期化処理用のToolにフォールバックされました。これは初期化Toolで、.serena/cache/python/ディレクトリにシンボルツリーの概要が保存されます。
続いて、Claude Codeは以下の順番でSerenaのToolを呼び出していきました:
list_dir- ディレクトリ構造の確認find_file- ファイルの検索find_symbol- ClojureLspクラスの具体的なコードを取得
その後、Claude Code標準のRead Toolでファイル全文を読み込み、最初のタスク「Clojure Language Serverのインストールパスを修正する」に着手しました。
修正作業の流れ
修正にはreplace_symbol_bodyが使われました。このToolは、特定のシンボルのコード全体を直接置き換えることができます。
次のタスクは「重複インストールを防ぐ機能の改善」でした。ここではinsert_after_symbolが活躍します。 指定したシンボルの直後に新しいコードを挿入できるため、置換元のテキストをコンテキストに含める必要がなく効率的です。編集ケースによってToolを使い分けているのがオシャレ。
さらに細かい修正にはreplace_regexが使われました。これは正規表現で関数内の特定部分を置換できるToolです。
テストとフォーマット
全ての編集が完了すると、Claude Codeは以下を実行しました:
uv run poe format- コードのフォーマット整形を実行するコマンド- インデントの不一致が大量に検出され、
replace_regexで修正
- インデントの不一致が大量に検出され、
poe test- ユニットテストの実行コマンド- インスタンスメソッドの定義エラーなどを修正
- 最終的にテストがパスして作業完了。お疲れ様でした。
この時点でのトークンカウントを見ると「85k/200k」でした。
/costコマンドのステータスが以下です。1タスクで$1.12かかりました。
/cost
⎿ Total cost: $1.12
Total duration (API): 5m 52.3s
Total duration (wall): 34m 56.1s
Total code changes: 52 lines added, 38 lines removed
Usage by model:
claude-3-5-haiku: 3.1k input, 114 output, 0 cache read, 0 cache write
claude-sonnet: 141 input, 19.0k output, 2.6m cache read, 112.7k cache write
claude-3-5-haikuが含まれるのはTaskツールのテキスト整形などの軽微な処理に付随するものです。「Vibing...」などのインジケーターに出す文言を推論しているためです(そんなとこにGPUを使うなよと思わなくはない)。
Serenaを使わない場合の比較
さて、実はここからが本番です。SerenaのMCP Toolを全く使用せずに同じタスクを実行しましょう。せっかく実施してもらったタスクを全て巻き戻し、Claude Codeを再起動して同じ指示を入力します。
まずTaskツールで作成された計画は前回と全く同じ内容でしたしかしその後はClaude Code標準のRead,Search,Editツールで修正を実行していきます。同じタスクをしたので比較できたのですが、こちらのが高速です。
修正過程はSerenaを使った時とほぼ同じです。同じSonnet4のモデルなので解法自体に違いはないのでしょう。
しかしpoe formatは一発で通りました。直感的にはファイルの全体から編集するアプローチの方がPythonのインデントを適切に扱えそうなのは理解できるところです。 その後ユニットテストもすんなり通し、作業完了です。インデント修正作業が発生しなかったからかトークン消費は「42k/200k」というSerena利用時の半分近くで済みました。
/costコマンドのステータスは以下です。タスクが短く済んだのでコストも$0.4357と半分以下になりましたね。
Total cost: $0.4357
Total duration (API): 5m 0.0s
Total duration (wall): 10m 22.6s
Total code changes: 52 lines added, 38 lines removed
Usage by model:
claude-3-5-haiku: 8.1k input, 147 output, 0 cache read, 0 cache write
claude-sonnet: 74 input, 10.1k output, 901.5k cache read, 33.5k cache write
この結果はSerenaを宣伝する上では期待に沿わないものですしかし実際のコーディングタスクはファイル関連ツールの呼び出し以外にも多くの処理が組み合わさります。
今回のタスクはPythonのインデント修正という派生問題が大きく結果に影響を与えました。ファイルのシンボル参照と書き込みというミクロな処理だけに注目するとSerenaのToolが理論上トークン効率が良いのは確かです。
なのでタスクの成否や言語・LSP・IDEの環境によって結果は左右されるのだと思います。仮に全く同じパスでファイル参照と書き込みの回数が一致するタスク結果になったとしたらSerena利用時のがトークンが削減されるはずです。ユーザー側の対処法もあり、例えばPythonのインデント修正だけ開いてるエディタやHooksで自動実行することはできます。
TIPS:Serenaのシステムプロンプトを手動で挿入する
Serenaが用意したToolを適切に呼び出してくれないときは、追加の指示をClaude Codeに伝えることが必要です。これはSerenaのinitial_instructionsToolに組み込まれています。
initial_instructionsが行うのは会話の中に特定のプロンプトのテンプレートを展開するだけです。内容は「SerenaのToolを使って最小の入出力でコードを編集しろ」というもので、CLIからserena print-system-promptを実行しても見られます。
ツールの完全な名前は「mcp_serena_initial_instructions」なので単にClaude Codeにチャットで「mcp_serena_initial_instructionsを呼んで」と依頼すれば実行してくれます。もしくはClaude Codeの起動時に--append-system-promptで渡したり、そもそもCLUADE.mdにシステムプロンプトを追加しておくという方法もあります。
# システムプロンプトを表示
uvx --from git+https://github.com/oraios/serena serena print-system-prompt
# 動的にシステムプロンプトを追加
claude --append-system-prompt $(uvx --from git+https://github.com/oraios/serena serena print-system-prompt)
本記事の検証ではinitial_instructionsで行う処理は内部的に解決されたので追加の設定を一切行いませんでした。
TIPS:SerenaのIndexを手動で更新する
Serenaのインデックス更新について、大規模なコードベースでは時間がかかるので、MCPサーバーの起動時には自動更新されません。 serena project indexコマンドを実行することで手動で行う方法もあります。これはLSPの解析結果をPklでシリアライズしてキャッシュしておくことで、Toolの処理が早くなるというものです。
❯ docker run --rm -i -v $(pwd):/workspaces/projects ghcr.io/oraios/serena:latest serena project generate-yml
❯ docker run --rm -i -v $(pwd):/workspaces/projects ghcr.io/oraios/serena:latest serena project index
Indexing symbols in project /workspaces/serena…
* Install prebuilt node (24.5.0) ..... done.
Indexing: 38%|███▊ | 29/76 [00:02<00:02, 21.77it/s]
Symbols saved to /workspaces/serena/.serena/cache/python/document_symbols_cache_v23-06-25.pkl
Deep Dive:Serenaの内部アーキテクチャ
ここからはさらに深く掘り下げてSerenaのアーキテクチャを解説します。重要なのは以下の2つのモジュールです。
Solid-LSP
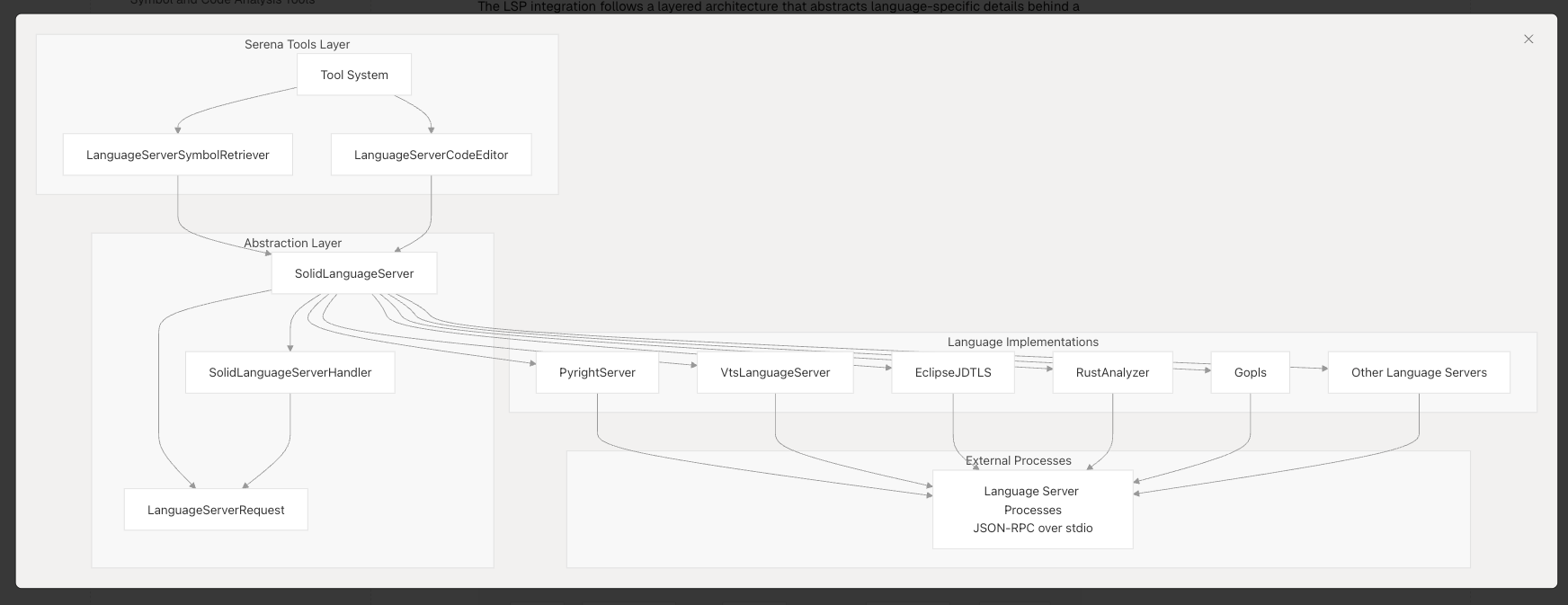
Serenaが複数の言語に対応したLSPの機能を呼び出せるのは、Solid-LSPという内部Pythonモジュールを独自実装しているからです。
Solid-LSPは各言語に対応したLanguage Server(PythonならPyright、TypeScriptなら公式Language Server)を適切に起動・管理し、シンボル検索機能を提供します。これはIDEが内部的に使用している機能と同等で、たとえば私たちがVS CodeでCmd-Tを押したときのシンボルジャンプや変数の一括書き換えといった操作をMCPツールとしてAIエージェントに呼び出せるようにします。
元々はMicrosoftのMultilspyライブラリをベースに開発されましたが、現在は独自実装に置き換わっています。現在は各言語サーバーを外部プロセスとして起動する方式ですが、将来的にはIDE内蔵のLSPへ直接接続する機能も検討されています。
現在Solid-LSPは各言語サーバーを外部プロセスを生成(spawn)しますが、[Feature] Support for projects with multiple languages by dynamic LSP switching によるとJetBrains PluginやVS Codeの拡張をリリースして、IDE側のLSPへ切り替える機能を検討しているようです。

CodeEditor
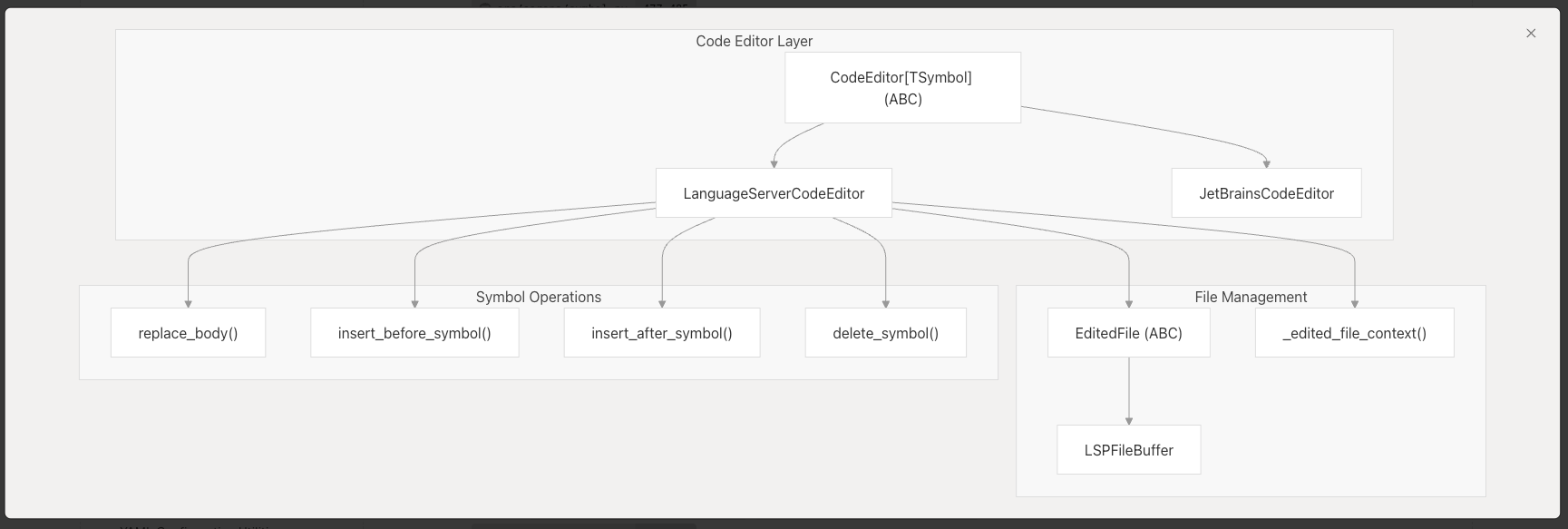
LSPは本来、シンボルの定義場所特定やリファレンス検索、補完候補提示といった情報提供に特化して設計されています。これらの機能はエディタからの問い合わせに対してソースコードの情報を返すことを想定しているからです。エージェントからのコードの編集命令をするような仕様は含まれていません。
しかし、SerenaではLSPから得たシンボル情報を使って実際にコードを編集する必要があります。特定の関数やクラスの中身を正確に置換するには、言語固有のパーサーや抽象構文木(AST)解析が必要です。
そこでSerenaはCodeEditor(LanguageServerCodeEditor)という独自のエディタレイヤーを実装しています。このモジュールがLSPから取得したシンボル情報をもとに、実際のファイル編集操作を実行する役割を担っています。
LSPによる構造理解と連携することで、「必要なシンボルだけ抜き出す」して「該当箇所だけ編集する」といった操作を実現し、余分なコンテキスト投入を削減しています。
おわりに
本記事では、AIエージェントが抱える「コードを単なるテキストとして扱う」という根本的な課題に対して、SerenaがLSPを活用してどのように解決を図っているかを解説しました。
シンボル検索やリファレンス追跡など、IDEレベルの高度な機能をMCPツールとして提供することで、コーディングエージェントの能力を向上させる狙いがあることがわかりました。
実際にClaude CodeからSerena MCPを使い、コード編集タスクのトークン効率を比較したところ、タスクレベルでは予想に反して「Serenaを使わない時のほうがトークン効率が良い」という結果になりました。
しかし、この結果はSerenaの価値を否定するものではありません。今回のPythonタスクではインデント修正という派生問題が大きく影響しましたが、言語やLSP環境によって結果は大きく変わる可能性があります。重要なのは、Serenaが示したアプローチである「LSPを使ったコードの読み書きの自動化」という課題と解決策そのものです。
Serenaの今後
SerenaのMCPを今すぐ使いこなさないと時代遅れのプログラマーになってしまうのでしょうか?そんなことはありません。
一般の開発者・エージェント利用者にとって、Serenaが行うのはあくまで内部的なコンテキストエンジニアリングの詳細であり、ツールとして使う分には意識する機会はありません。その恩恵においても本記事が示したとおりタスクの過程や結果に左右されています。
開発元のOraios AIはSerenaを収益性のあるビジネスにするには至っていませんが、Serenaはまだ実験段階中の製品というステータスです。しかし、Serenaが構築しようとしている「AIエージェント向けのIDE」という領域には大きな可能性があります。特にChatGPTがローカルMCP対応を実装すれば、非プログラマのビジネスユーザーも含めた幅広い層がSerenaのようなヘッドレスコーディングツールの恩恵を受けられるようになるでしょう。
また、Serenaプロジェクトとしては、Agno(Langchainのようなエージェントフレームワーク)でワークフローシステムに組み込むことで、エンタープライズ向けのビジネスに進出する余地もあります。
AIエディタ戦争におけるSerena
VS CodeやCursorといった既存のAIエディタは、すでに独自の方法でシンボル検索機能を活用しています。Copilot ChatはVS Codeの機能をRPCで呼び出し、Cursorは独自のインデックスと埋め込み表現でコードベース理解を実現しています。
Serenaはこれらのエディタと競合するものではなく、むしろ補完的な関係にあります。しかし、AIエディタの進化は速く、お互いのユースケースが重なる可能性もあります。実際、Claude Codeにもすでに検索のためにRipGrepをパッケージに含めたり、ClineやCopilot ChatにはTree-sitterによるAST解析Toolを内蔵しており、将来的にLanguageServer統合を追加する可能性も十分に考えられます。そうなれば、ユーザーがSerenaのMCPサーバーを追加で組み込む必要性は薄れるでしょう。
筆者個人としては、ファイル編集というコーディングの中核機能は、エージェント本体に組み込まれ、ベンダー自身がメンテナンスする方がセキュリティ面でも好ましいと考えています。そのため、現時点でSerenaを常用する予定はありません。
しかし、SerenaにはAIエディタベンダーがまだ公開していないLSPを使ったコード操作の実装例として、大きな価値があります。エージェント開発者にとっては貴重なリファレンス実装であり、AIがLSPでファイル編集を行うというアプローチは、今後のAIエディタ開発の重要な指針となるでしょう。
更新履歴
- 25/08/04 Claude CodeとTree-sitter関する記述を訂正(きのすけさん)