『LLMのプロンプトエンジニアリング』を読んだ
最近日本語翻訳が発売された書籍『LLMのプロンプトエンジニアリング ―GitHub Copilotを生んだ開発者が教える生成AIアプリケーション開発』を読みました。その感想です。

どんな人におすすめか
本書は、AIエージェントのフレームワークやライブラリを自作したい、システムの内部構造を詳しく知りたいという人におすすめします。一方で、既存のフレームワークを使ってサービス開発を目指す人には他に適した書籍があるでしょう。
前提知識
事前知識については、私はWeb系エンジニアで機械学習の専門知識はないが、TransformerやGPTの仕組みを大まかに理解しており、OpenAIやClaude、Geminiといった主要なモデルのAPIを用いて生成AI(LLM)アプリケーションを開発できます。
本書は言語モデルそのものの詳細な内部構造には深く踏み込まず、「こういう経緯でTransformerモデルができました」という簡単な説明から解説が始まります。
『Ⅰ部 基礎』はLLMの歴史から
「Ⅰ部 基礎」はLLMの歴史から、LLMアプリケーションとはなんなのかという原理・原則の話です。テキスト補完モデルの生成対象が、会話形式の文書を生成するチャットモデルへと変化しました。次に、チャットモデルが生成するテキストをRLHF(人間のフィードバックによる強化学習)とChatML形式でマークアップして、我々が知るChatGPTのような人間相手に会話できるLLMアプリケーションに生まれ変わります。
技術的には、この会話形式の文書の制約中で現在のエージェントのツール呼び出しなど、すべてのワークフローが実現されていることが分かると、こんな柔軟な仕組みをよく考えたものだと感心します。
LLM とトレーニングデータの関係
本章では「LLMはトレーニング中に見たテキストパターンを入力テキストに応じて再現するもの」という原則が繰り返されます。ここから、使っているモデルがどのようなデータセットで学習されているかを知ることが、LLMを使いこなす近道なのではないかと思いました。
しかし商用モデルはブラックボックスなので中身を知るにはベンダー(プロバイダー)が公開しているベストプラクティスなどのドキュメントを手掛かりにするしかありません。たとえば、私はモデルのアップデートがあった直後には、以下のような提供元サイトを真っ先に確認するようにしています。


「『Ⅱ部 中心的なテクニック』
「Ⅱ部 中心的なテクニック」はプロンプトエンジニアリングという言葉を聞いた時に思い浮かべそうなテクニックが豊富に解説されているパート。たとえば「回答のためのコンテキストを入れる」「書式をXMLやMarkdownで表現」や「logprob値を取ってモデルの確信度を評価する」など。
前パートの感想でも触れましたが、過渡期なのでこのあたりのベンダーがAPIやSDKで提供する機能を真っ先に使いたい場合にマルチプロバイダ系のラッパーフレームワークを使っていると対応できなくて、やはり直接提供元のモデルに近いツールを使うのがいいなと最近は思っています。最近では、Claude 3.7でExtended Thinking(<thinking />)用の独自パラメータが追加された際に、もどかしさを感じました。

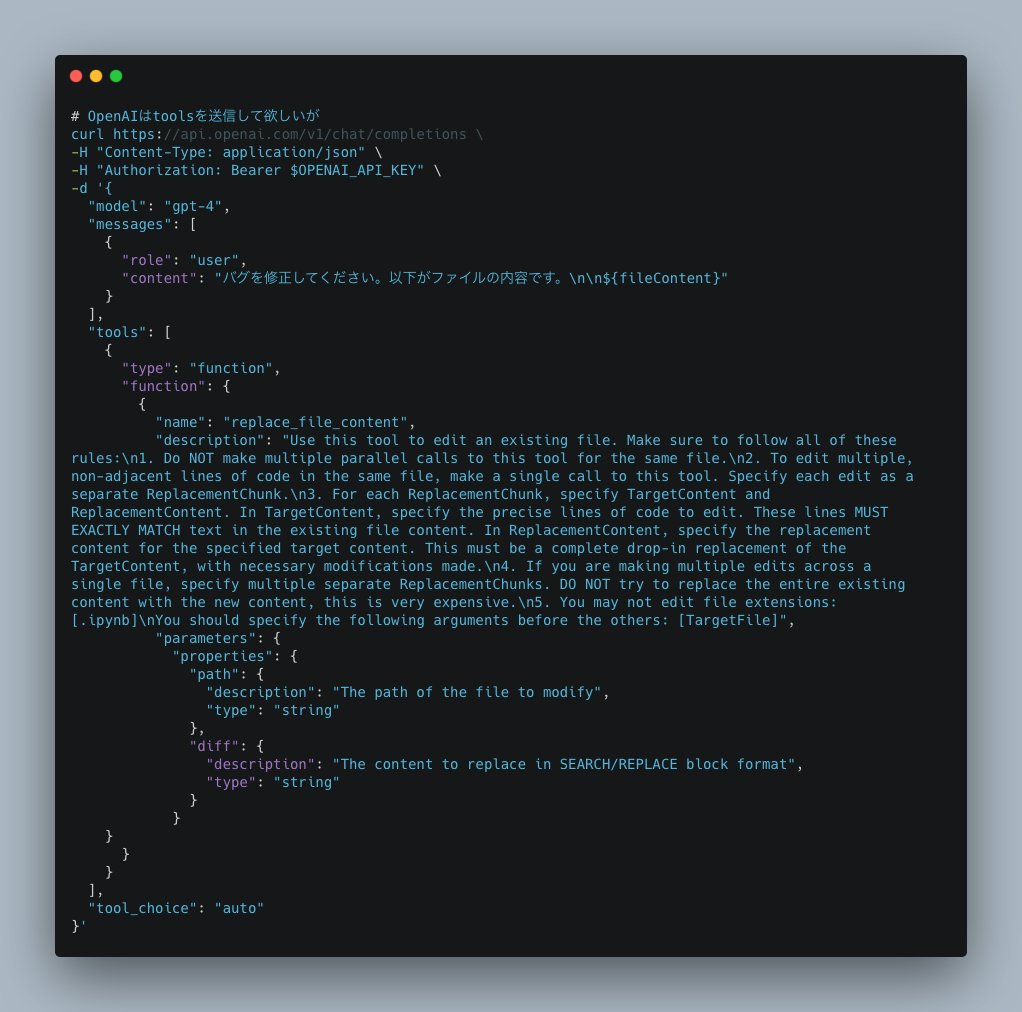
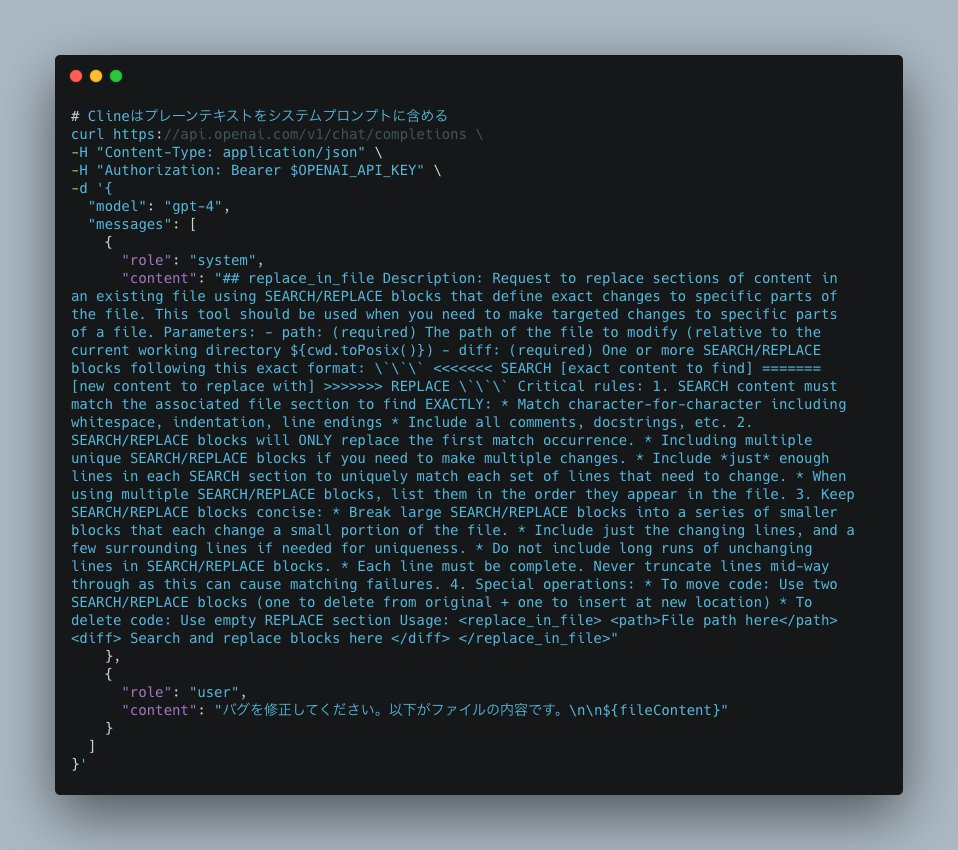
コード生成関連でいうとOpenAI系(GitHub Copilot)とAnthropic系のプロンプトにおけるDiff表現がことなります。GPT-4.1はV4A形式でトレーニングされているのでCopilot Agentがそれに最適化されているとClaudeやGeminiと差が出そうですし。

またClineで機能するClaude系のプロンプトはプレーンテキストにXMLで表現したパラメータを埋め込み、レスポンスでパースします。おそらくGeminiもこの方式に適合しているはずです。
これはOpenAIがSDKで想定しているAPIパラメータの受け渡し方式とは異なります。OpenAIのモデルが正規のAPIパラメータ経由での入力に最適化されている場合は、結果が変わってくるでしょう。このような調整が必要かどうかは、モデル開発元が提供するツールを直接使ってみないと分からないのです。
プロンプトエンジニアリングについて
そしてプロンプトエンジニアリングについての認識を改めました。私はこの言葉は「チャットボットに指示を出す文章術」程度の理解だったが、本書の定義は異なりました。
本書のプロンプトエンジニアリングは「LLMの出力をユーザーの問題解決に適合させる技術」という部分にフォーカスしています。そのための手段としてプロンプト(入力トークン)が使われると説明されていました。
先の原則のとおり、モデルのトレーニング過程を知らずして精度向上は難しいです。プロンプトエンジニアリングの目的は、ユーザーの入力をモデルが機能するトレーニングデータに沿ったデータに変換することです(単にデータエンジニアリングという名前でもよいと思いましたが)。
また、LLM自身が学習データの特徴をよく把握しているのを駆使すると、OpenAIが提唱するmeta promptingのように、LLM自身にLLMに与えるプロンプトを生成させるアプローチも存在することを知りました。

「『Ⅲ部 プロンプト作成のエキスパート』
「Ⅲ部 プロンプト作成のエキスパート」は実践編に立ち入りコード例が出てくる楽しいパートです。会話型エージェントやLLMワークフローなど読者が想像するLLMアプリケーションっぽいものが登場します。LLMにスキーマを渡して呼び出し方法を推論してもらうツールコーリングもでてきますし、会話履歴バッファ管理するコードなども登場します。実際、このようなアプリケーションを開発する時はAI SDK やMastraなどのサードパーティを駆使することになりそうですが。
LLMワークフローとエージェント設計
しかし一転「9章 LLMワークフロー」は理論的な話が多く興味深かったです。この章は「AIエージェント」と聞いた時に想像するシステムやアーキテクチャの話になります。
本書では「シンプルなワークフローからはじめよう」という標語のもと大きなタスクをそれぞれ小さなタスクに分解して、それぞれをモジュールとして実装すると良いと解きます。タスクはLLMで制御せずとも順番に決まった順番で実行すればよく、内部実装もLLMを使う使わないをそれぞれ選択してまずはシンプルさを追求して自動化せよという戦略は私の好みとも合致しました。その後の発展的な話題として、LLMのエージェント自身にタスクのオーケストレーションをさせ、より複雑な問題に向かいます。
この説明の中で個人的に興味深かったのは「ワークフローを制御するためにユーザーに会話型エージェントを提供する」という部分です。チャットアシスタントに指示を出してツールを呼び出し、会話で結果を見るという従来のシステムとは出発点が異なり、主従関係が逆だという感想を持ちました。
2025年5月時点の関連アップデート
本書が刊行された2024年11月から2025年5月にかけて、LLM業界であった関連する重要なアップデートを見てみます。
Reasoning/Extended Thinking 系モデルの登場
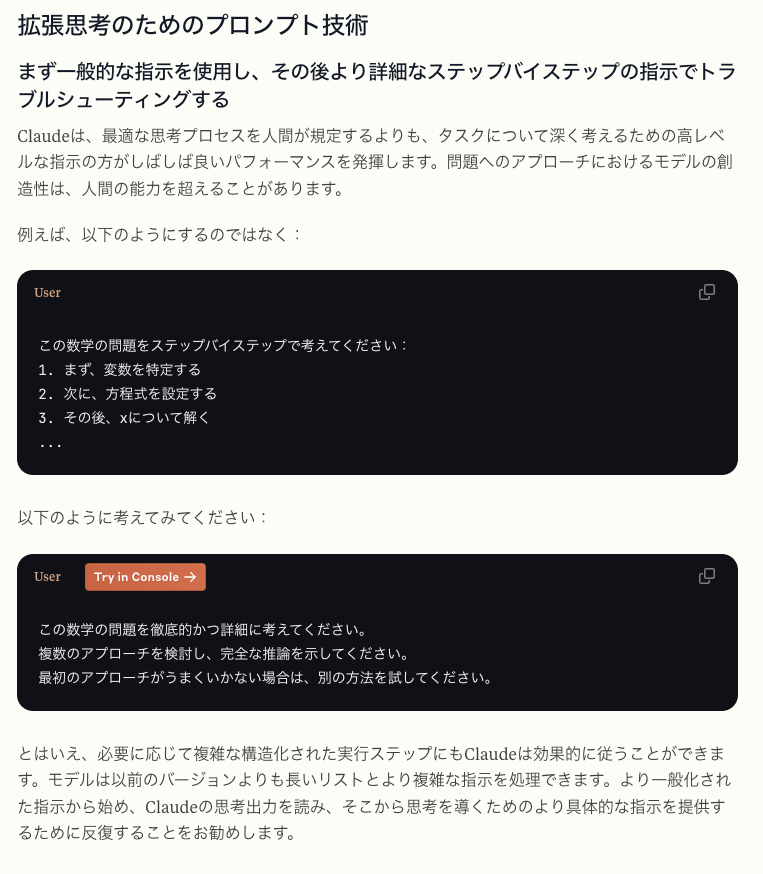
まずReasoning / Extended Thinking系モデルの登場 (例: 2024年12月5日 OpenAI o1 シリーズ)がありました。これらではプロンプト内で明示的に「ステップバイステップで考えてください」といったCoTを誘導する指示を記載する必要が薄れていることが知られています。
「ステップバイステップで考える」ようにモデルに指示するなど、いくつかのプロンプトエンジニアリングテクニックは、パフォーマンスを向上させない可能性があり(そして、時には阻害する可能性があります)。
https://platform.openai.com/docs/guides/reasoning-best-practices#how-to-prompt-reasoning-models-effectively
コンテキストウィンドウの拡大
次にGemini 筆頭のロングコンテキストウィンドウ (例: Gemini Proの200万トークン)サポートがあります。本書時点では長大なコンテキストを使用する際のベストプラクティスが多数ありましたが、場合によってはすべてをコンテキストに収めて動作させることが可能になりました。

エージェント向け API の進化
またAIエージェント・ワークフローに関しても2025年以降のMCPサーバーの動向や、GPT-4.1などのモデルはAgentic workflows向けのトレーニングを重ねておりツール呼び出し性能の向上がみられます。
GPT-4.1は、エージェント的なワークフローを構築するのに最適なモデルです。モデルの訓練においては、多様なエージェント的問題解決の軌跡を提供することに重点を置きました。また、このモデルに対する私たちのエージェントハーネスは、SWE-bench Verifiedにおいて非推論モデルとしては最先端の性能を達成しており、55%の問題を解決しています。
https://cookbook.openai.com/examples/gpt4-1_prompting_guide
OpenAIのResponses APIは、特にo3やo4-miniといったReasoningモデルにおいて、リクエスト間でコンテキストを保持することに向いています。Chat Completion APIがステートレスであるので発展的なアップデートです。AIエージェント向けのAPIで活用することになりそうなので本書Ⅲ部に関連します。
拡散テキストモデル
Google DeepMindから「拡散テキストモデル Gemini Diffusion」が発表されました。本書の前提はTransformerモデルなので自己回帰的に生成しない拡散モデルは根本的にプロンプトエンジニアリングが変化するのではないかと考えています。

しかし本書で解いているのはなぜそのプロンプトがLLMで有効なのか? という点や、アプリケーションレイヤーの問題をモデルレイヤーに変換するためのステップや考え方の部分にあると思うので、無駄にはならないでしょう。
おわりに
『LLMのプロンプトエンジニアリング』では、Transformerベースの言語モデルが現在のAIエージェントまでどのように進化したのか、というのをモデルの外部から入出力を行い監査する第三者からの視点で学べる良書でした。私はエージェント分野のツールを作ったり調べたりするのが好きなので今後その活動に活かして行けたら良いと思っています。AIエージェント開発をしたい同士の皆さんはぜひ本書をお手に取ってみてください。
