作って使うAIエージェント —— Pi Coding Agentで足りない機能を自作しよう

Pi Coding Agentは、Mario Zechner氏が開発しているOSSのターミナル型コーディングエージェントです。

なぜ今Piを紹介するのか。
コーディングエージェントは、Claude Code、Codex、Cursor、OpenCode、Hermes Agent、OpenClawなど選択肢が増えました。
一方で、関心はモデル単体の性能だけでなく、モデルをどう動かすかというハーネス層にも移っています。継続実行ループ、常駐ジョブ、サブエージェント、メモリ、検索、外部ツールをどう組み合わせるか、という話です。
この背景には、最高性能モデルのリリースが以前ほど単純ではなくなっていることもあります。OpenAIの次期モデルでは安全性確認を理由に段階的提供が報じられ、AnthropicのFable 5 / Mythos 5でも輸出管理に伴うアクセス制限が報じられました。
最先端モデルを待つだけではなく、自分用のハーネス環境を持ち、モデル、tool、memory、検索、実行ループを組み替えられることが重要になっています。Sakana AIのFuguのように、外側のオーケストレーションで性能を引き出す試みもあり、薄いハーネスですぐ試せること自体に価値があります。
便利な機能が最初から入ったエージェントを選ぶ方向はもちろんあります。ただ、使っているうちに「自分のログを検索したい」「Xを検索したい」「Tailscale内のローカルLLMを呼びたい」のような、自分の環境に寄った要望も出てきます。
以前書いたOpenClawの何が特別なのか?では、OpenClawがPiをエージェントランタイムとして採用していることに触れました。また、『作って学ぶAIエージェント』の宣伝記事でも、Read / Write / Edit / Bashの4ツールだけで構成されたミニマルな実装例としてPiを取り上げました。
この記事では、そのPiを実際に使いながら、もう少し掘り下げます。Piは一般的なコーディングエージェントというより、足りないAI機能を自分で作って使うためのハーネスに見えます。
この記事の要点
- Pi Coding Agentはターミナルで動く小さめのコーディングエージェントです
- 標準機能を巨大にするより、TypeScriptのextensionで育てる設計です
- command、tool、hook、UI、providerなどを追加できます
- SkillsやMCPより、エージェントのランタイム側に近い場所を拡張できます
- はてなブックマーク検索やWeb検索を実際に追加してみました
- 使い込むほど、汎用エージェントから自分用のハーネスに近づきます
Pi Coding Agentとは
Pi Coding Agentは、ターミナル上で動くコーディングエージェントです。
公式READMEでは、Piは「minimal terminal coding harness」と説明されています。
公式ドキュメントでも、Piは小さいコアをTypeScript extension、Skills、Prompt Templates、Themesで拡張するものとして説明されています。

デフォルトでモデルに渡される主要な道具はシンプルです。
readwriteeditbash
必要に応じて、CLI側ではgrep、find、lsなども使えます。
モデルがファイルを読み、コマンドを実行し、必要なら差分を書き込みます。
ここだけ見ると他のコーディングエージェントと同じですが、Piの面白さは「最初から全部入り」ではなく、利用者がextension、skill、prompt、theme、packageを足していく前提のところにあります。
もうひとつ重要なのは、抽象レイヤーの薄さです。
Piは、LLM APIに近いところへ最小限のtoolを渡し、その結果をそのまま扱う構成に見えます。
特定のプロバイダー固有の体験を厚く作り込むのではなく、tool callingできるモデルに薄く接続するアプローチです。
そのため、新しいモデルやプロバイダーを試すときに、モデルそのものの挙動を見やすいです。
たとえばOpenRouterのモデル一覧を見ていると、毎日のように新しいモデルが追加されていることがわかります。こうしたモデルを自分の作業環境で評価する足場として、Piの薄いハーネスはちょうどよいです。

インストールとモデル設定
インストールはnpmでできます。
npm install -g --ignore-scripts @earendil-works/pi-coding-agent
--ignore-scriptsはnpmのinstall scriptを実行しないための指定です。Piは通常のnpm installではinstall scriptを必要としないため、公式READMEでもこの形が示されています。
起動したら、モデル+プロバイダーを設定します。
/login
/model
PiはAPIキーだけでなく、既存サブスクリプションを使ったログインにも対応しています。
公式のprovider docsでは、サブスクリプション認証として以下が挙げられています。
https://pi.dev/docs/latest/providers
- ChatGPT Plus/Pro(Codex)
- Claude Pro/Max
- GitHub Copilot
先頭にあるのでPiがCodexをデフォルトのおすすめにしている、というわけでもなく。各ユーザーの選択は様々です。
Piの作者Mario Zechnerや、Piの開発元であるEarendilに参加したArmin Ronacherの公開発言を見ても、特定の1モデル固定というより、その時点で良いモデルを切り替えて使う姿勢に見えます。
MarioはPiを日常のコーディング作業の中心に置きつつ、Claude Code、Codex、Gemini、ローカル/OSS系モデルを比較対象にしています。
ArminもPi向けの個人パッケージを公開しており、Claude CodeやCodexなど複数のCLIエージェントを併用していることを書いています。

つまりPiの考え方は、特定モデルへの依存というより、モデルを差し替えられるハーネスを手元に置くことに近いです。
APIキーで使う場合は、Anthropic、OpenAI、Google Gemini、OpenRouter、Vercel AI Gatewayなど、多くのプロバイダーを設定できます。
モデルについて
その上で、筆者が最初の入口としてすすめるなら、ChatGPT Plus/ProのGPT系モデルです。Codexのサブスクリプションとして使われているものです。
https://chatgpt.com/plans/plus/
これをすすめるのは、性能だけでなく今のところ利用規約で明確に禁止されていないからです(逆に言うと今後制限され始める可能性もあります)。
Claude Pro/Maxの外部ハーネス利用は、2026年春に扱いが揺れました。一度はOpenClawなどの利用が通常のPro/Max枠から外れ、extra usage扱いになりましたが、その後一部戻る動きも報じられています。
GitHub CopilotもPi側ではproviderとして対応しています。ただし、Copilotサブスクリプションを外部ハーネスの汎用モデルプロバイダーとして使うことについて、GitHub公式の明示的な許可は筆者の確認範囲では見つけられていません。この記事ではおすすめしません。
しかし、ここでPiの設計が活かせます。Pi Coding Agentは、基本的にはLLM APIにtoolを生やす最小構成のハーネスです。特定モデルに深く依存しているというより、LLM APIへの薄いラッパーとして使える性質があります。
そのため、OpenRouter、Vercel AI Gateway、DeepSeek、Gemini Flash、中国系コーディングプラン、xAI Grokなど、tool callingできるモデルや互換APIを試しやすいです。
この感覚は、拙著『作って学ぶ AI エージェント』で扱ったLLM API抽象化レイヤーにも近いです。LLMにmessagesとtoolsを渡し、tool callが返ってきたらプログラム側で実行し、結果をまたLLMに返す。Piはその基本形に近い位置で動いているため、モデルやプロバイダーを差し替えたときの挙動を観察しやすいです。
新しいモデルが出たときも、OpenAI Chat Completions互換APIやResponses API互換など、既存のLLM API形式に乗っていれば、provider設定を足すだけで試せます。
とくにChat Completions互換APIは多くのプロバイダーが採用している形式なので、新しいモデルを試す入口になりやすいです。
たとえばSakana AIがFugu / Fugu UltraをOpenAI互換APIで提供したとき、筆者の環境でもbaseUrl、apiKey、modelsを定義するだけでPiから使えるようにできました。
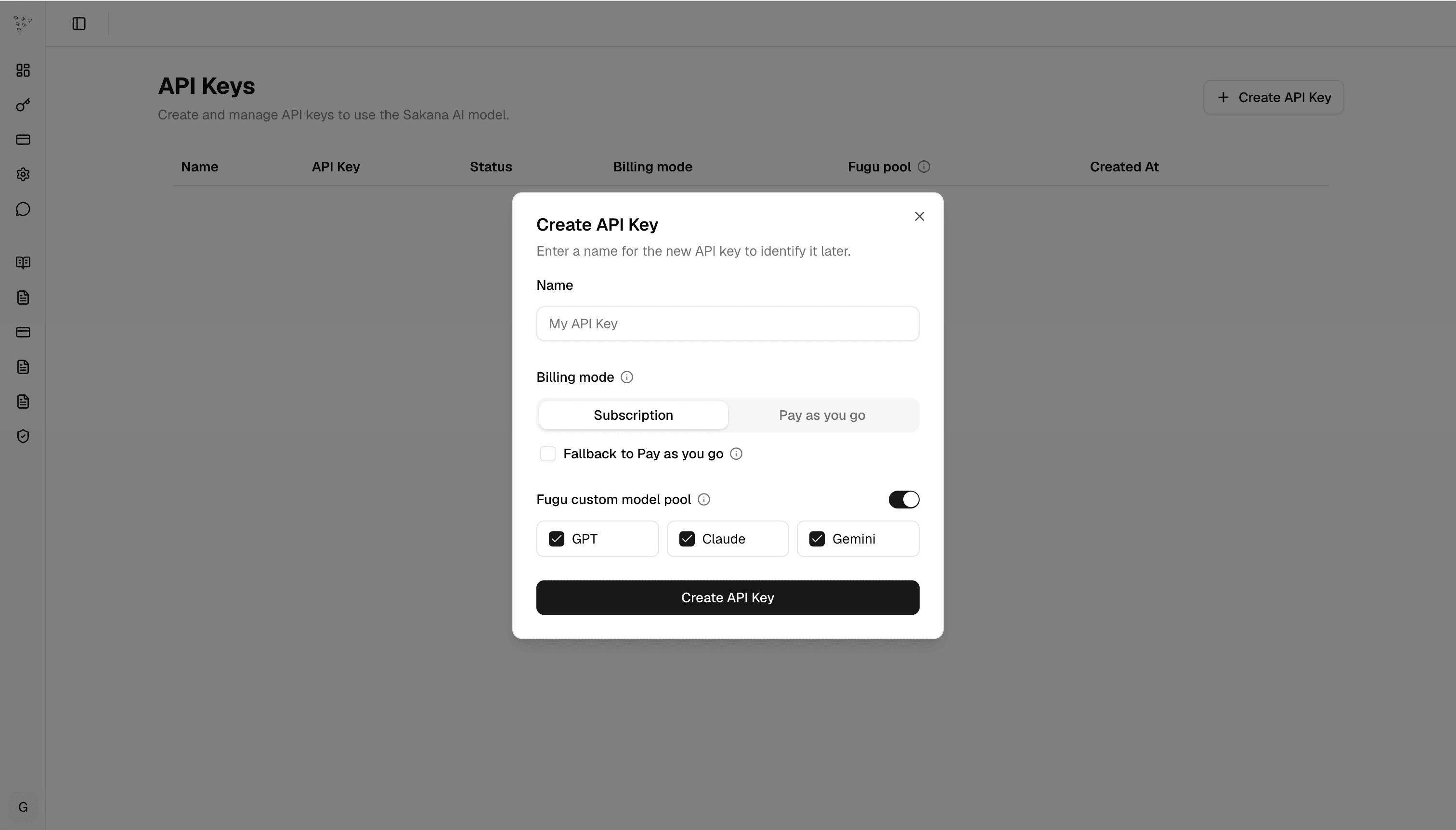
{
"providers": {
"Sakana AI Console": {
"baseUrl": "https://api.sakana.ai/v1",
"api": "openai-responses",
"apiKey": "$SAKANA_API_KEY",
"models": [
{ "id": "fugu", "name": "Sakana Fugu" },
{ "id": "fugu-ultra", "name": "Sakana Fugu Ultra" }
]
}
}
}
Piの本質はextensionsで拡張していくこと
Piの特徴はextensionにあります。
ここでいうextensionは、単なる設定ファイルやプロンプト、SKILL、MCPツールの追加より範囲と権限が広いです。
TypeScriptコードをPiの実行時に読み込み、Piが公開しているAPIを呼び出します。
たとえば以下のようなものを登録できます。
| 追加できるもの | API |
|---|---|
| スラッシュコマンド | pi.registerCommand() |
| LLMが呼べるtool | pi.registerTool() |
| 実行途中のhook | pi.on(...) |
| UI表示 | ctx.ui.setStatus(), ctx.ui.setWidget()など |
| モデル接続先 | pi.registerProvider() |
Piのextension APIは公式ドキュメントにもまとまっています。

Piのextensionは、この表のようにPi本体の周辺へ機能を差し込む仕組みです。独自の図を増やすより、ここでは公式docsのAPI一覧に寄せて説明します。
完成品のコーディングエージェントなら、用意された設定項目を変更して使います。
Piの場合は、自分のワークフローに合わせてランタイムの振る舞いを足していきます。
XではPiのアーキテクチャを「agent harness界のVim」や「Emacsっぽい」と呼ぶ人もいます。
軽量で、ターミナルに馴染み、素の状態から自分で育てる手触りはVimに近いです。
一方で、TypeScriptでランタイムを拡張して自分用の環境を作っていく感覚はEmacs的でもあります。
Piの面白さは、足りないAI機能をextensionや外部CLIとして作り、自分の作業環境に組み込めるところにあります。
SkillsやMCPとの違い
エージェントを拡張する仕組みとして、SkillsやMCPもあります。
Skillsは、作業手順や知識をテキストとして渡す仕組みです。
LLMが読む情報を増やすのに向いています。リソースとしてファイルが配備でき、エージェントがCLIの実行をするガイドになります。
MCPは、外部プロセスがtools、resources、promptsを提供する仕組みです。
LLMが呼べる外部関数を増やすのに向いています。決まった手続きをプログラム化できます。
双方ともLLMが呼び出すツールやコマンドを決め、実行しますがエージェントの内部処理までは干渉しません。
Piのextensionは、Piのプロセス内でTypeScriptモジュールとして読み込まれます。
そのため、toolを追加するだけでなく、hookで実行途中に処理を挟んだり、UIを更新したり、providerを追加したりできます。
Pi本体が「MCPを最初から内蔵する」のではなく、必要ならextensionとして作る、という思想なのも特徴です。
このあたりが、Piを完成品のコーディングエージェントというよりハーネスとして見る理由です。
command、tool、hook
Pi extensionでは、command、tool、hookの役割が分かれています。commandはユーザーが手で呼ぶ操作、toolはLLMが作業中に呼ぶ機能、hookはPiの実行中イベントに反応する処理です。
たとえばnotion_searchというtoolを追加しておくとします。Notion APIにはページやデータベースを横断するSearch endpointがあります。
ユーザーが「この仕様に関係するNotionの設計メモを探して」と頼むと、LLMはnotion_searchを呼び出し、結果を見ながら次の作業に進めます。同じ検索機能を/notionのようなスラッシュコマンドとして公開すれば、ユーザーも手で呼び出せます。
この対称性がPi extensionの扱いやすいところです。検索、記憶、ログ収集、外部エージェント連携のような機能をtoolとして足しておくと、Piは必要なタイミングでそれらを呼びながら作業を進められます。単発の便利機能だけでなく、継続実行ループやループエンジニアリングの部品にもなります。
hookで実行中に処理を挟む
hookを使うと、エージェントの実行途中に処理を挟めます。
実用例としてはログ収集があります。
Web検索toolを追加した場合、検索クエリ、返ってきたURL、処理時間をJSONLに残しておくと後から見直しやすいです。
pi.on("tool_call", async (event) => {
if (event.toolName !== "web_search") return;
await appendJsonl(".pi/logs/search.jsonl", {
type: "search_call",
input: event.input,
at: new Date().toISOString(),
});
});
pi.on("tool_result", async (event) => {
if (event.toolName !== "web_search") return;
await appendJsonl(".pi/logs/search.jsonl", {
type: "search_result",
content: event.content,
at: new Date().toISOString(),
});
});
こうしておくと、エージェントがどの検索結果を見てコード修正に進んだのかを追えます。
単にtoolを増やすだけでなく、エージェントの動作を横から観測できるのが便利です。
はてなブックマーク検索を追加した
実際に、はてなブックマーク検索用のextensionを作ってみました。
はてなブックマーク検索を足す理由は、Google検索とは別のソースが取れるからです。
はてブには、日本語圏でコメントしたくなる話題、一部の人がクリップして保存する有益なまとめ、技術者コミュニティで話題になった記事が集まりやすいです。性質としてはReddit、Hacker News、掲示板的な情報流通に少し近いところがあります。
そのため、一般的なSearch APIだけでは拾いにくい、日本語中心の反応や文脈を補えます。
使っているのは、はてなブックマーク検索RSSです。
https://b.hatena.ne.jp/search/text?mode=rss&q=<検索語>
このextensionでは2つの機能を追加しました。
| 機能 | 説明 |
|---|---|
/hatena <query> |
ユーザーが手で呼ぶコマンド |
hatena_bookmark_search |
LLMが必要に応じて呼べるtool |
流れはこうです。
1. Piに「はてブ検索toolを作って」と頼む
2. PiがTypeScript extensionを書く
3. `.pi/extensions/hatena-bookmark.ts`ができる
4. `/reload`で読み込む
5. 以後、LLMが`hatena_bookmark_search`を呼べる
ここがかなり面白かったです。
OpenClawユーザーなら、この感覚はすでに体験しているはずです。OpenClawもPiをランタイムとして採用しているため、エージェントに自分が使う道具を作らせる流れが自然に出てきます。
検索機能を使うだけなら普通のツール追加ですが、Piでは「エージェントに道具を渡す」だけでなく、「エージェントに自分自身の道具を作らせる」方向に寄せられます。
Web検索も追加した
同じ考え方で、一般的なWeb検索も追加できます。
Web検索機能は、多くの場合モデルプロバイダー側の検索バックエンドに紐づいています。
OpenAIならBing系、GeminiならGoogle Search grounding、xAIならWeb SearchやX Search、という具合です。
Pi extensionとしてWeb検索toolを作る場合は、この検索バックエンド、つまりSERP APIを自分で選べます。
Piに専用のWeb検索toolがなくても、Brave Search API、Serper、Tavily、Exa、SearXNG (複数の検索サービスの結果を集約するメタ検索)などを呼ぶextensionを書けばよいです。
今回考えたweb_search toolはこの形にしました。
web_search({
query: string,
maxResults?: number
})
まずはSearXNGを使うextensionを実装しました。
~/.pi/agent/extensions/web-search.ts
これで、ユーザーがURLを明示しなくても、LLMが必要に応じてWeb検索できます。
Next.js 15のcache invalidationについて調べて、移行時の注意点をまとめて
このように頼むと、エージェントはweb_searchを呼び、検索結果を見ながら回答やコード修正に進めます。
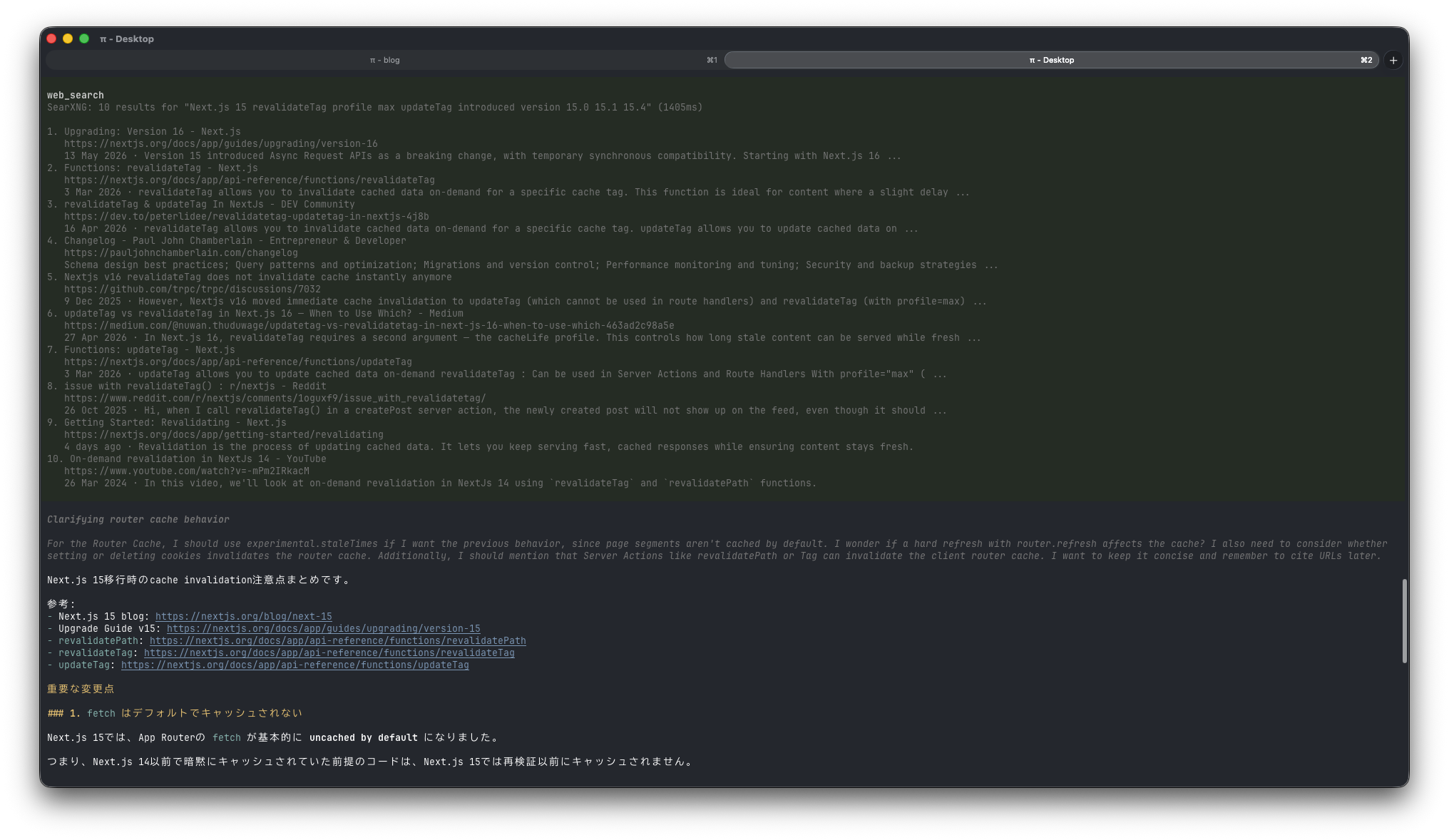
Web検索の有無は、コーディングエージェントの実用性にかなり効きます。
組み込み機能として待つのではなく、自分の使いたい検索バックエンドをextensionで差し込めるのは便利です。
X検索も追加した
Hermes Agentには、xAIのx_searchを使ったX検索機能があります。
同じ発想の機能は、Piでもextensionとして追加できます。
xAIのx_search自体は公式APIとして提供されているtoolです。

Responses APIのtoolsとして使う方法も公式ドキュメントに載っています。
この記事ではサブスクリプションOAuthではなく、XAI_API_KEYを使ってPi extensionからxAI Responses APIを直接呼ぶ形にしました。
注意として、この方式はAPIキーを使うので従量課金です。
Hermes AgentのSuperGrok / X Premium+ OAuth連携のように、サブスクリプション枠を使う方式とは違います。
試す場合は、xAI APIの課金設定、上限、利用量を確認してから使う必要があります。
~/.pi/agent/extensions/x-search.ts実装全体を載せると長いので、ここでは要点だけにします。あなたのPiに上記URLを渡すなどして作ってもらってください。
XAI_API_KEYを環境変数から読むhttps://api.x.ai/v1/responsesを呼ぶtools: [{ type: "x_search" }]を渡す- Pi側には
x_searchtoolと/xsearchcommandの両方を登録する
const response = await fetch("https://api.x.ai/v1/responses", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.XAI_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: process.env.XAI_X_SEARCH_MODEL || "grok-4.3",
input: [{ role: "user", content: `Search X for: ${query}` }],
tools: [{ type: "x_search" }],
}),
});
Piを起動する前にAPIキーを渡します。
export XAI_API_KEY="xai-..."
pi
Pi側ではx_search toolと/xsearchコマンドが追加されます。
/xsearch Hermes Agent Nous Research
実際に試すと、Piは通常の会話から自律的にx_search toolを呼び、X上の投稿URL、投稿者、時刻、要約を返せました。
xAI x_search: Hermes Agent Nous Research
**Here are 10 relevant X posts/threads about "Hermes Agent" by Nous Research** (an open-source, self-improving AI agent framework with persistent memory, skill learning, and recent features like Mixture of Agents/MoA presets). I
prioritized highly relevant results from semantic and keyword searches (exact phrases and close matches). All are directly on-topic.
1. **Author**: Wes Roth (@WesRoth)
**URL**: https://x.com/WesRoth/status/2069676907822821775
**Date**: June 24, 2026
**Note**: Directly announces Nous Research releasing "/learn" for Hermes Agent, turning source material into reusable AI skills.
2. **Author**: Wes Roth (@WesRoth)
**URL**: https://x.com/WesRoth/status/2049277483472887909
**Date**: April 29, 2026
**Note**: Covers Nous Research introducing "Creative Suite" for Hermes Agent, including native TouchDesigner integration for generative art.
3. **Author**: Patrick Bucquet (@pbucquet)
**URL**: https://x.com/pbucquet/status/2070161092853027325
**Date**: June 25, 2026
**Note**: Reports on Nous Research launching 'blank slate mode' in Hermes Agent for enhanced control and secure deployments.
つまり、Hermes Agentが持っているX検索体験を、PiでもAPIキー方式のextensionとして再現できます。
ここでも重要なのは、Pi本体にX検索が標準で入っているかどうかではありません。
必要な検索機能を、自分のAPIキー、自分のログ方針、自分の使い方に合わせて足せることです。
Tailscale内のサーバーと連携する
筆者の環境では、自宅のWindows PCでLM Studioを動かし、Tailscale経由で手元のPiから呼べるようにしています。GPUを持つ別マシンの計算資源を使えるうえ、外部APIに送りたくないログやメモをローカルLLMに投げる選択肢もできます。
VPS側にはOpenClawやHermes Agentのような常駐型エージェントも置いています。これらの作業結果はファイルとして保存し、手元のPiから参照できます。
PiはインタラクティブなCLIハーネス、VPS上のエージェントは常駐ジョブやバックグラウンド処理、という役割分担です。Pi extensionにしておけば、内部APIを呼ぶtoolにも、共有ファイルを読むtoolにもできます。
作って使う: 足りないAI機能をどこに足すか
この見方をすると、Piは「AI機能が少ないコーディングエージェント」ではなく、「AI機能をユーザーランドで足すための土台」に見えます。
その前提にあるのが、Piがあえて持たないものです。
Piがあえて持たないもの
PiのREADMEを読むと、あえて最初から入れていないものも目立ちます。
たとえば以下のようなものです。
- MCP
- sub-agent
- plan mode
- built-in todo
- permission popup
- background bash
これらを単に不要だと言っているというより、Pi本体に固定の形で入れない、という思想に見えます。
READMEや作者の発言を見ていると、MCP、sub-agent、plan mode、built-in todo、permission popupのような機能には、それぞれ作者なりの意見があるように見えます。
ただし、ユーザーから要望は出ます。
そこでPiは「本体に入れる」ではなく、「必要なら自分で追加できるようにする」方向へ振っています。
ここがプラグイン機構のよいところです。
必要ならextensionで作るか、Pi packageとして入れる。
backgroundプロセスが必要ならtmuxを使うなど。
TODOが必要ならTODO.mdを書くか、自分のワークフローに合うDB連携を作る。
Piのリポジトリを見ると、この思想はサンプルコードにも出ています。
packages/coding-agent/examples/extensions/plan-mode/には、plan modeをextensionとして実装する例があります。
packages/coding-agent/examples/extensions/dynamic-tools.tsには、起動後にtoolを追加する例があります。
packages/coding-agent/examples/extensions/reload-runtime.tsには、LLMが呼べるtoolから/reload相当のコマンドを後続メッセージとしてキューに積む例があります。
つまり、Piに「足りないAI機能」がある場合、それは単に未実装というより、利用者が自分のワークフローに合わせて足す余地として残されている面があります。
この割り切りは好みが分かれそうですが、筆者はかなり好きです。
「全員に同じ高機能UIを配る」のではなく、「小さいコアを自分の作業環境に合わせて組み替える」方向だからです。
何をextensionにするべきか
ただし、何でもPi extensionにすればよいわけではありません。
- LLMが呼ぶ道具はtoolにする
- ユーザーが呼ぶ操作はcommandにする
- 実行中の観測や制御はhookにする
- Piのプロセス外のOS権限が絡むものなどは外部CLIにする。
この置き場所を設計できるのが、Piをハーネスとして使う面白さです。
メモリレイヤーを作ってみる
たとえば、エージェントに過去の作業を思い出させるメモリレイヤーが欲しくなります。
筆者はcmanというツールを作っています。
これは、Claude CodeやPi Coding Agentの過去セッションログを検索して、以前の作業を思い出すためのツールです。
これは、いわゆるエージェントのmemory機能です。
ただし、Pi本体にmemoryが組み込まれているわけではありません。なので、欲しくなったタイミングで自作します。
そうしてできたものを配布する仕組みも備えています。
cmanをPi packageとして入れると、Pi側には/rememberや/cm-statusのようなコマンドが追加されます。
pi install git:https://github.com/laiso/cman.git --approve
これで、Piは過去のClaude Codeセッション、Piセッション、メモリファイルを横断して探せるようになります。
音声入力もしたい
音声入力も欲しい機能のひとつです。Claude CodeやCodexにはありますが、Pi本体にはありません。
ただし、音声入力は必ず自作する必要はありません。macOS/Windows標準の音声入力や、Superwhisperのような商用アプリで十分な場合も多いです。辞書登録、用語補正、入力先ごとの挙動は商用アプリが強いです。
筆者は、使うモデルやAPIを自分で選びたかったため、whisttというCLIアプリを作りました。将来的にはTailscale内のローカルGPUマシンで音声認識モデルを動かす構成も考えています。
これはPi extensionではなく外部CLIです。マイク権限、OS入力、常駐処理、ショートカット、クリップボード操作が絡むため、Piの外に置いた方が自然だからです。
Web検索、X検索、社内API検索、RAG、ブラウザ操作、チケット管理連携のような機能も、Pi本体に入るのを待つのではなく、自分の環境に合わせて足せます。Piが面白いのは、こうした追加機能が単なる外部コマンド呼び出しではなく、command、tool、hook、UI、providerとしてエージェント実行環境に入るところです。
セキュリティ面の注意
extensionはTypeScriptコードとして実行されます。
つまり、便利な反面、信頼できないextensionやPi packageを入れるのは危険です。
これはプロンプトや決まった仕様のテキスト構造ではなく、実行コードそのものです。
Skillsのようなテキスト指示でも危険はありますが、Pi extensionはさらに直接的にローカルファイル、シェル、認証情報に触れる可能性があります。
公式ドキュメントでも、外部packageはソースを確認してから入れるよう注意されています。
自作extensionでも、APIキーの扱い、ログに残す内容、外部APIに送る情報には気をつけた方がよいです。
APIキーは外部から読む
例えば、Brave Search APIを使うときはAPIキーが必要になります。
Piの認証情報は~/.pi/agent/auth.jsonに置けます。
ただし、APIキーをファイルに直書きしたくなかったので、筆者はBitwarden CLI経由で読むようにしました。
{
"brave-search": {
"type": "api_key",
"key": "!bw get password brave-search-api-key"
}
}
Piを起動する前に、同じshellでBitwardenをunlockします。
$env:BW_SESSION = bw unlock --raw
bw sync
pi
auth.jsonには実キーではなく、キーを取得するコマンドだけを書きます。
このあたりも、設定値だけでなくローカルの認証ワークフローまで含めて自分用に寄せられるところです。
Web検索はハーネス設計の一部
Web検索については、個人用に立てたSearXNGでしばらく実験してみるつもりです。
ただし、SearXNGは裏側で各検索エンジンに問い合わせるメタ検索エンジンなので、公開インスタンスへのただ乗りや大量自動アクセスには注意が必要です。
安定運用や商用利用では、Brave Search API、Serper、Tavily、Exaなどの公式API/SERP APIも試したいです。
検索バックエンドによって、エージェントが拾う情報やコード修正の成功率が変わる可能性があります。
Cursorは最近、コーディングベンチのスコアがモデルの推論能力だけでなく、Web検索やGit履歴探索による“reward hacking”で上がる場合があると指摘しています。

これはベンチマークだけの話ではありません。
普通の開発タスクでも、エージェントが外部参照するWeb情報の質によって成果物は変わります。実装方針、移行時の注意点、既知の不具合、ライブラリの最近の変更は、モデル内部の知識だけでは追いきれません。
レポート作成や文章執筆でも同じです。何を検索し、どの情報を拾い、どう要約して使うかで出力は大きく変わります。昔から言われる “Garbage in, garbage out” の話です。
私たちに身近なタスクほど、Web検索連携は思った以上に大きなウェイトを占めます。だからWeb検索toolは、単なる便利機能ではなく、ハーネス設計の一部として扱った方がよいと思っています。
また、音声入力については、Tailscale内のローカルGPUマシンで音声認識モデルを動かす構成も試したいです。
ただし、検索バックエンド比較や音声認識バックエンド比較はベンチマーク設計まで含むので別記事にします。
この記事では、Piがそうした実験をしやすい構造を持っていることだけを押さえておきます。
まとめ
Pi Coding Agentは、完成品のコーディングエージェントというより、自分用のAI機能を作って使うためのハーネスです。
はてブ検索、Web検索、X検索、メモリレイヤー、音声入力、Tailscale内のローカルLLM連携のような機能を、自分の環境に合わせて足せます。
モデル単体の性能だけでなく、tool、memory、search、loopをどう組み合わせるかが重要になるなら、Piのような薄いハーネスはよい実験台になります。
