GPT‑5 Codexがリリース
OpenAIが2025年9月15日にGPT‑5 Codexを発表しました。GPT‑5 CodexはGPT‑5を土台にして、エージェントのコーディング能力に適した学習と強化が加えられたモデルです。長時間の自律的な作業に特に強みがあります。
We’re releasing new Codex features to make it a more effective coding collaborator:
— OpenAI Developers (@OpenAIDevs) August 27, 2025
- A new IDE extension
- Easily move tasks between the cloud and your local environment
- Code reviews in GitHub
- Revamped Codex CLI
Powered by GPT-5 and available through your ChatGPT plan.
現在はChatGPTの有料プランで利用可能で、Codex CLIやCodex Cloudの標準モデルとしても採用されています。API経由での提供はまだ始まっていませんが、近く提供される見込みです。
OpenAIはgpt-5以前にCodex Cloudで使えるo3ベースのcodex‑1とCodex CLIで使えるo4-miniベースのcodex-mini-latestというモデルをリリースしています[1]。これがGPT‑5 Codexというバージョンに全て置き換わった形です。
[1]: https://openai.com/ja-JP/index/introducing-codex/
この記事では、筆者はChatGPT Plusの環境でCodex CLIとCodex Cloudを試し、ベンチマークやコードレビューでの挙動を検証しました。Claude Code+Opus 4.1との比較も交えつつ、特徴と導入判断の観点をまとめます。
GPT‑5 Codexの改善点
大規模リファクタリング性能
まず、大規模なコードベースを理解して編集する能力が向上しました。複数ファイルにまたがる変更を伴うリファクタリングで、GPT‑5と比べて正解率が向上したと説明されています(数値で言うと%GPT‑5: 33.9%に対してGPT‑5 Codex: 51.3)。
OpenAIが例に挙げるのは、Giteaの2022年のプルリクエストです。このような実在のコミットを、Codex CLIのようなエージェントへ指示するだけでどこまで再現できるか、という観点で検証されていると理解しています。
加えて、Latent SpaceのGreg Brockmanへのインタビューでは、現実のOSSでメンテナーの協力を得て、モデル同士の成果物をブラインドで比較する「New Evals」という評価の構想も紹介されています。コード生成評価のデファクトであるSWE‑benchやAider polyglotは生成するコードサイズも小さく、実際のエージェント型コーディングの能力を正確に測れていません。現場の作業に近いコンテキストで比較することが重要だいうのは筆者も以前から主張していることです。

コードレビュー精度の向上
次に、コードレビューの精度です。GPT‑5 Codexはレビューに特化した追加学習を受けており、コードの依存関係をたどったり、テストの実行を通じてレビューの正確さを確認したりできます。OpenAI内部による比較では、レビュー時の誤った指摘が減り、重要な指摘の割合が増えたという説明が付されています(誤指摘率13.7%→4.4%、重要指摘率39.4%→52.4%)。
この件と関連して、Codex CLIには「/review」というコマンドも追加され、レビュー指示のショートカットができました。私の検証環境では、Opus 4.1では気づけなかった潜在的な問題を、GPT‑5 Codexは指摘することがあり(後述)、実務の補助としての期待値が上がったと感じています。
Codex Cloudにもこのコードレビュー機能が組み込まれており、設定画面から有効化できます。プルリクエストで @codex をメンションして、実行することも可能です。

GPT‑5 Codexの検証
Codex CLIのタスク実行時間の上乗せ
| モデル構成 | 平均実行時間 (秒) | 備考 |
|---|---|---|
| codex + gpt‑5‑codex (high) | 204.5s | 300秒タイムアウトで失敗あり |
| codex + gpt‑5‑codex (high) +「300秒以内に完了」プロンプト | 114.2s | プロンプト制約で短縮 |
| codex + gpt‑5 (high) | 156.7s | 安定して完走 |
筆者が運用しているエージェント向けベンチマーク「ts‑bench」でも挙動を確かめました。これはTypeScriptコード演習25問を使って、エージェントとモデルの組み合わせごとに正解率と実行時間を測る仕組みです。GPT‑5単体でも満点に到達しうる手応えはあるのでスコアの上限値ではなく実行時間に注目しました。
最初に、GPT‑5 CodexとCodex CLIを組み合わせた場合、GPT‑5と比較し、実行時間が延びてタイムアウト300秒に至ることが多くありました。タイムアウトを延長すると正しく成功するので、GPT‑5 Codexに変更したことで作業時間の上乗せが起きていると考えられます。
そこで、プロンプトに「タスクを300秒以内に終わらせてください」と補足すると、実行時間が短縮されました。OpenAIの説明どうり、思考トークンの量やツール呼び出し回数をモデル自身が見積もる傾向があるため、作業調整の手がかりになるようです。
少なくともts‑benchの問題の難易度では、この時間短縮によって正解率が下がることはありませんでした。ただし、プロンプトで都度調整するより、reasoning_effortの設定を下げる、あるいはモデル自体を軽量な系列に切り替えるといった手段のほうが、運用上の優先度は高いと考えます。
Codex Cloudのタスク時間上限
Codex Cloudのタスク時間についても触れておきます。Cloud側ではモデルを選択できず、コード編集やコードレビューはGPT‑5 Codexが標準で使われます。OpenAIはGPT‑5 Codexについて「最大で7時間以上の独立実行が可能」と説明していますが、私のChatGPT Plusのアカウントでは、1時間を超えるような規模のタスクは実行が拒否されました。これは過去記事でふれたts‑benchのデータソースである演習問題を101問に拡張したタスクです。実際にDevinは1時間以上かけてタスクを実施します。
そこで実験として、プロンプトベースで「作業を分割してください」と再提案すると、Codexの判断で問題を3つ選出し、およそ8分間は動作しました。さらに30分程度の粒度に明示的に分けた場合でも、8分前後で中断されました。これらの挙動から、内側に別の制約が存在していると推測しています。おそらく、契約プランや実行条件によって、この上限は変わるのだと思います。ChatGPT Proのアカウントの方は是非8分超のタスクを試してみてください。
コードレビューをClaude Codeと比較
Codex CLIの「/review」コマンドとClaude Codeの「/security‑review」(Opus 4.1)を比較しました。 ts‑benchのリポジトリで、セキュリティレビューが必要なDockerコマンド連携の改修プルリクエストを題材とします。 リポジトリ全体は1万行弱で、プルリクエストは1000行の変更があります。
結果はClaude Codeはセキュリティ問題なしを報告、GPT‑5 Codexは脆弱性の問題はないとしつつも、シェルスクリプトコマンドの引数と実装ロジックの誤差を検出し、特定の引数の時期待どうりプログラムが動作しないことを報告しました。以下が実行時ログです。Claude Codeは最終報告のみですが、Codex CLIは思考過程もターミナルに出力されています。

Claude Codeについてはレビューがセキュリティ面にフォーカスしているため、網羅的にチェックしている範囲が異なるように見えます。
おわりに
最後に、導入判断の観点を簡潔にまとめます。Codex CLIを使う前提では、最高品質のコーディングを狙うならGPT‑5 Codexが最有力の選択肢になります。Claude Code+Opus 4.1の組み合わせを置き換え得るレベルといえます。
その一方で、より多くの思考量が効くぶん、待ち時間が増える場面があります。短いフィードバックループを最優先する場合は、reasoning_effortを下げるか、gpt‑5‑mini系への切り替えを検討するとよいと思います。タスクの性質に応じて、CLIやCloudで長時間実行をするのか、手元のIDE拡張でモデルを頻繁に切り替えながら使うのか、などの選択があります。
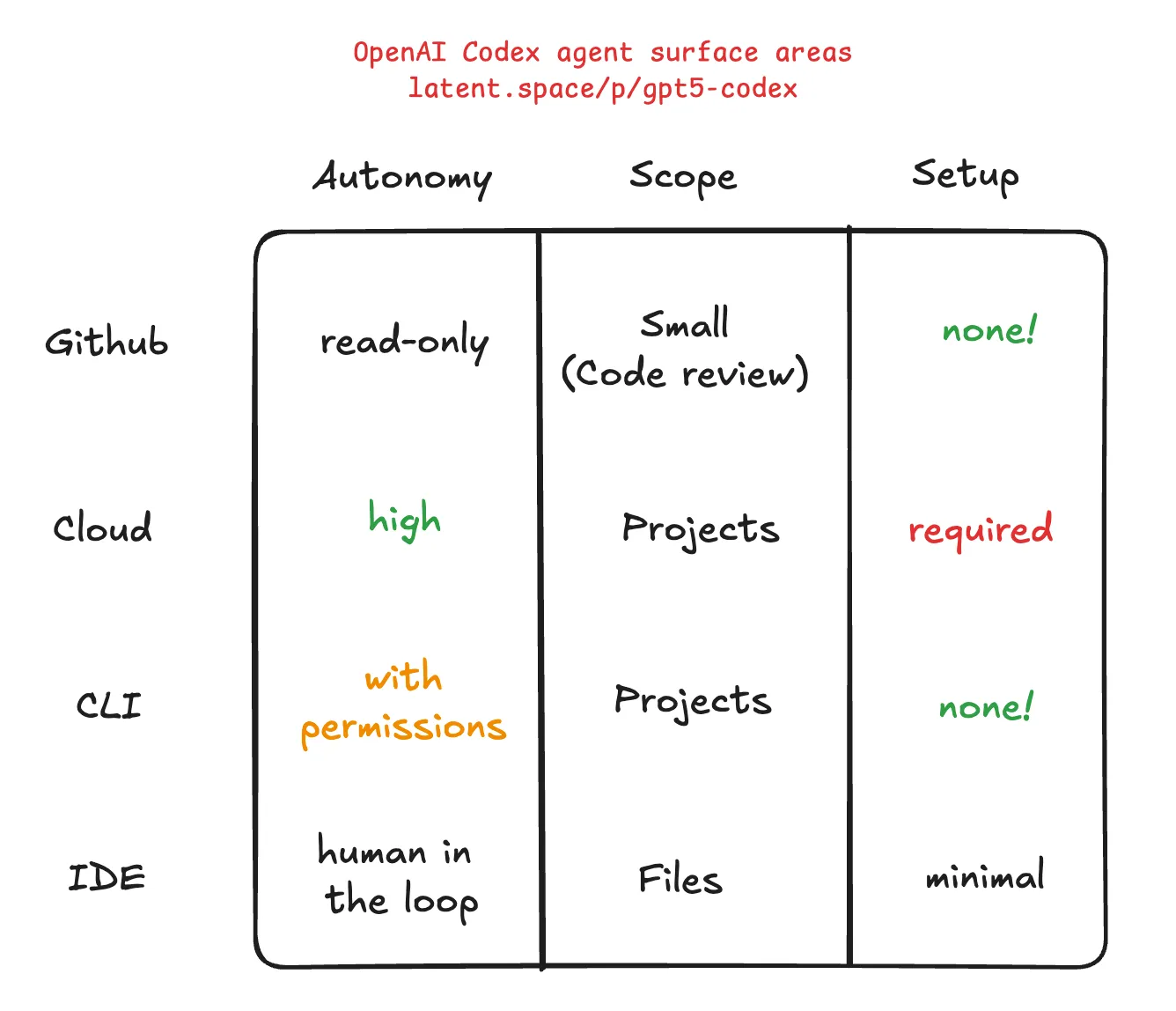
前述のLatent Spaceの記事に素晴らしい比較表が掲載されていますので引用します。自律性、範囲、導入コストの観点でどのインターフェイスを選択すると良いのかの指標になります。