Gemini 3 Proはデザインに強いのか?
Gemini 3 ProとClaude Opus 4.5のリリースが近かったこともあり、世間ではこの2つのモデルの性能比較が盛んに行われていました。中でもクリエイターたちの意見で目立ったのは、「Gemini 3 Proの方がOpus 4.5よりもUIデザインが得意だ」というものでした[1]。
[1]: Design Arena で4部門でトップ、Xランドでの言及も多い。
少なくともGemini 2.5 Pro以前は、UIデザインの評判はClaude Sonnetの独壇場だったはずです。v0やBoltといった多くのサイト作成サービスにSonnetが採用されていることからも、それは明らかです。
ではGemini 3 Proの登場で状況は変わったのか? というのを自分で確かめてみることにしたのが本記事の趣旨です。
なおここで作成したウェブサイトはVercelにデプロイしています。各モデルが生成したUIを以下から実際にブラウザで確認できます。
結論から言うと、UI再現タスクでは Claude Opus 4.5 が最も高精度かつ安定していました。Gemini 3 Pro は悪くないものの「当たり外れ」があり、次点です。以下では、実際のスコア・条件・比較方法を詳しく解説します。
なぜ「Gemini 3 ProはUIに強い」と言われているのかを考える
筆者自身も持っていた「GeminiはUIに強い」という感覚は、主に以下の理由がありました。
Nano Banana効果?
ひとつは、Geminiがマルチモーダルに注力していることから来る「画像認識が得意なら、コード生成も得意だろう」という安直な連想です。
Nano Banana(Gemini 2.5 Flash Image)のリリース時にGoogle社によて展開された大規模なマーケティングは、Geminiの画像生成能力の高さを強く印象づけました。この「画像に強い」というパブリックイメージが、いつの間にか「UIデザインも強い」という期待にすり替わっていた部分は否めません。
公表されているベンチマーク結果
Googleのベンチマークによれば、Gemini 3 ProはUI理解テスト「ScreenSpot-Pro」で72.7%を記録し、Claude Sonnet 4.5(36.2%)やGPT-5.1(3.5%)を大きく上回りました。Figma MakeやReplitといった主要ツールがGeminiを採用しているのも納得できます。

なぜ「UI再現」で比較するのか
本記事で行った「UI再現」というタスクは、モデルの能力を測るベンチマークとして筋が良いと考えています。
まず、UI模写にはモデルの構造理解・レイアウト精度・空間認識といった複合的な能力が要求されます。ただ画像を見て「何が写っているか」を説明するのではなく、その視覚情報を構造化されたコードとして出力しなければなりません。
プロトタイピング、既存UIの自動修正、ノーコードツールでのデザイン生成——こうしたユースケースでは「カンプ通りに出せるか」が直接的に価値につながります。
一方で、サイトデザインに含まれる画像素材をTailwindCSS表現の図形で代替させる点には「本来なら素材セットを用意して人間がレイアウトするようにコーディングした方が正確になるのか?」という懸念もありましたが、実際には画像領域の扱いによるスコア変動はごく小さく、評価結果への影響は限定的であることを確認して、この方針にしました。
検証方法
今回は「DribbbleのUIデザイン画像1枚を基準として、各モデルにNext.jsのページで表示する Tailwind CSSベースのコンポーネントとして再現させ、スクリーンショットをpixelmatchで差分を測定する」という方法を取りました。
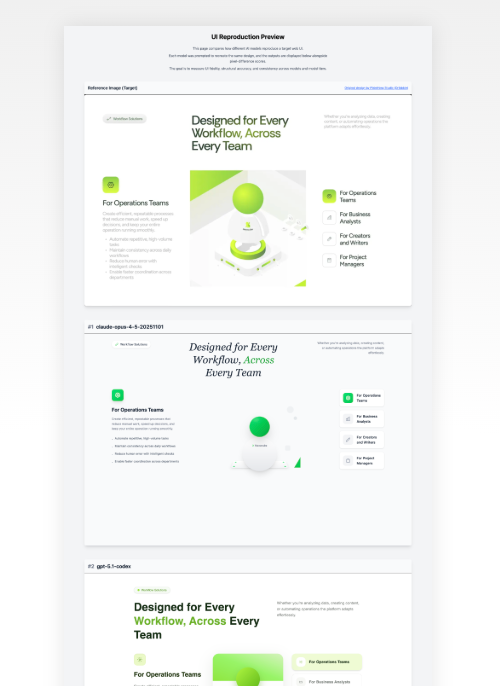
題材としたのは以下の「Nexocube - AI Intelligence Platform」のデザイン画像です。これは単にDribbbleのトップページから自分で選びました。
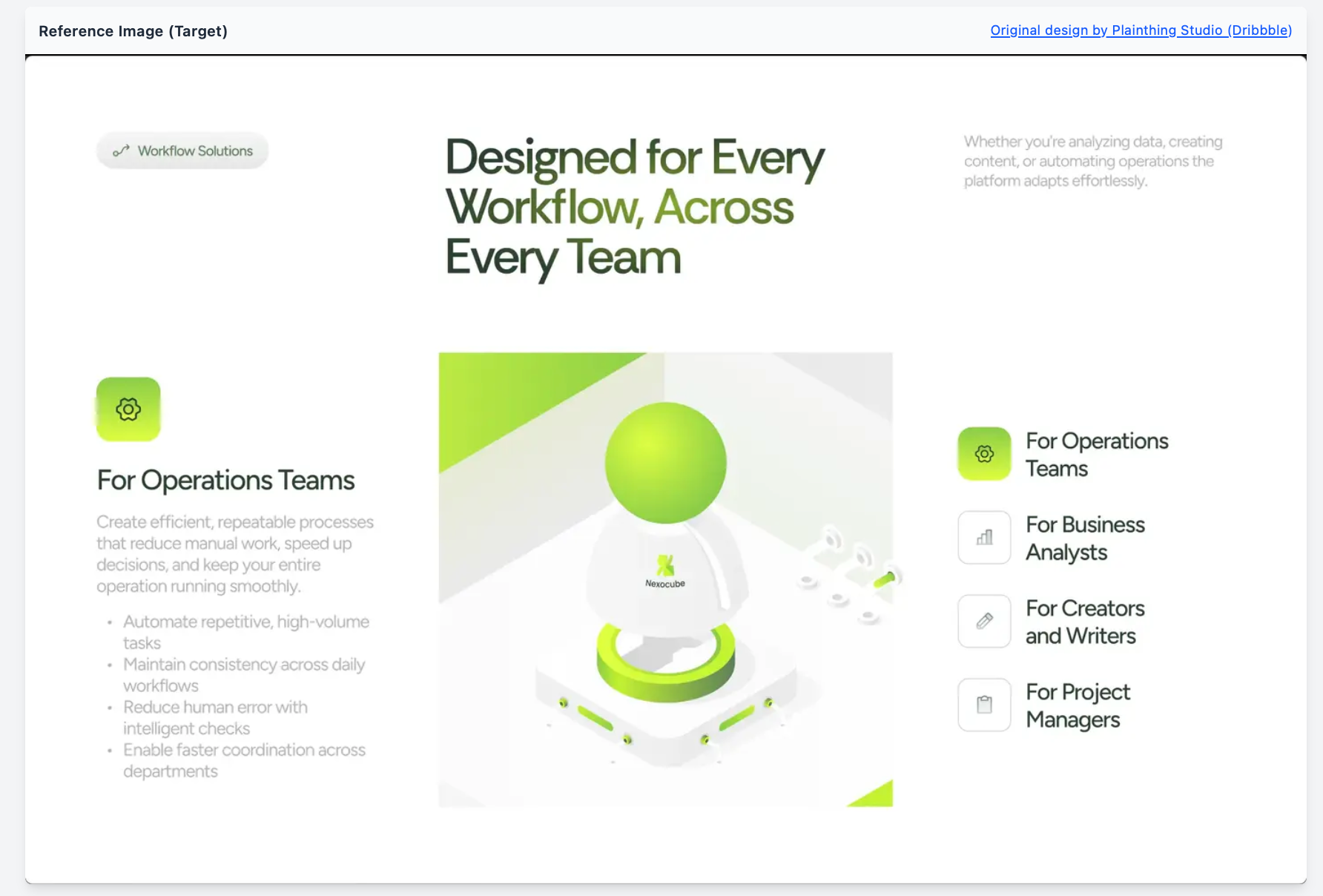
デザインの基準画像の選定
この基準画像は、ある程度意図を持って選定しています。
まず、情報量が多いこと。色数、要素の密度、階層構造、カードレイアウト、余白のバリエーション、タイポグラフィの使い分け——こうした要素が1枚の中に詰まっているデザインを選びました。シンプルすぎるデザインだとモデル間の差が出にくく、複雑すぎると全員が崩壊して比較になりません。
次に、モデルの苦手領域が露出しやすい構造であること。ネストしたカード、微妙な余白の違い、アイコンとテキストの位置関係——こうした「ちょっとした判断ミス」が累積してスコアに反映されるデザインです。
最後に、特定のモデルが得意・不得意になりにくい中庸なデザインであること。たとえば極端にミニマルなデザインや、特殊なアニメーションを多用したデザインだと、特定モデルの学習データに偏りが出る可能性があります。なので今回は「Hero系のレイアウトの製品ページの一部」を選ぶことで、公平性を担保しようとしました。
比較対象となるモデルを選ぶ
各社の最高性能モデルであるPro枠として Gemini 3 Pro、Claude Opus 4.5、GPT-5.1 Codexの3つ。Fast枠として Claude Haiku 4.5、GPT-5.1 Codex Mini、Gemini 2.5 Flashの3つ。合計6モデルです。
プロンプト
全モデルに投げたプロンプトは以下の1本だけです。画像を添付してVercel AI SDKで同じ処理を回しました。
添付したUI画像を Next.js + Tailwind CSS で忠実に再現してください。
レイアウト、余白、色、比率を可能な限り維持してください。
Next.js プロジェクトは pages/ ディレクトリ構成です。
生成するコードはすべて pages/index.tsx の中に収めてください。
外部ファイル(CSS, component, public assets)は使用しないでください。
これのレスポンスからTSXをパースしてファイルに保存します。
Next.js + Tailwind CSSを選んだ理由
この組み合わせを選んだのには理由はまず、UI自動生成タスクとして現実的な設定であること。v0をはじめとする多くのAI UIツールがこのスタックを採用しており、モデルたちも大量の学習データを持っているはずです。
もうひとつは、モデルの言語的な判断がダイレクトに出力に反映されること。Tailwindはユーティリティファーストなので、flex justify-between items-center のような記述が直接DOM構造とレイアウトを決定します 。CSS-in-JSのような抽象化レイヤーがない分、モデルが「この要素はflexで横並び、子要素は両端揃え」と判断したことがそのままコードに現れる、と考えました(諸説あります)
スクリーンショット取得
Playwrightで viewport 1440px、deviceScaleFactor 1 の条件でスクリーンショットを取得。これを基準画像と比較して差分スコアを算出しました。
技術的な詳細:
- ページロード待機:
waitUntil: 'networkidle'で全リソースの読み込み完了を待機 - スクロール位置:
scrollTo(0, 0)でページトップに固定 - 画像形式: lossless PNG
- ブラウザ: Playwright内蔵のChromiumを使用
画像サイズの統一
基準画像と生成画像のサイズが異なる場合があります。生成されたページの高さはモデルによって異なるためです。
この問題に対処するため、比較時には両画像の小さい方に合わせてクロップしています。具体的には、基準画像が1440×931pxの場合、生成画像も左上から1440×931pxの領域を切り出して比較します。この処理は全モデル共通です。
サンプル数と安定性評価
各モデルに同じ画像を10回生成させ、平均だけでなくスコアの振れ幅(最小・最大)も評価しています。
LLMのUI生成は、回によるブレが非常に大きいです。同じプロンプトを投げても、ある回では再現率が上がっても、別の回では構造ごと崩壊することがあります。
実務で重要なのは「毎回同じ品質で返してくれる」ことです。プロトタイピングツールやノーコードサービスでは、ユーザーが生成ボタンを押すたびに結果が大きくブレるようでは使い物になりません。だから平均だけでなく、スコア幅も重要な評価軸として扱います。
pixelmatchスコアの読み方
結果を見る前に、このスコアが何を意味するのか明確にしておきます。
pixelmatchはMapbox社が開発した画像比較ライブラリで、ビジュアルリグレッションテストなどで広く使われています。2つの画像をピクセル単位で比較し、差分の割合を0〜1で返します。スコアが小さいほど画像の一致度が高いです。位置のズレや色のわずかな差も検出されるため、かなりシビアな評価になります。

このスコアは「画像を正確にHTML化する能力」を測っています。モデルが元のデザインを"より良くした"場合でもスコアは悪化する——つまり忠実度だけを見ています。
結果
| 順位 | モデル | 平均スコア | 最小 | 最大 |
|---|---|---|---|---|
| 1 | Claude Opus 4.5 | 0.0896 | 0.0841 | 0.0959 |
| 2 | Gemini 3 Pro | 0.1083 | 0.0950 | 0.1372 |
| 3 | GPT-5.1 Codex | 0.1207 | 0.0902 | 0.1921 |
| 4 | Gemini 2.5 Flash | 0.1228 | 0.1011 | 0.2033 |
| 5 | GPT-5.1 Codex Mini | 0.1234 | 0.0955 | 0.1409 |
| 6 | Claude Haiku 4.5 | 0.1261 | 0.1096 | 0.1449 |
※スコアは0に近いほど基準画像に近いことを意味します。
この表の見方
この表を見るときは、平均スコアだけでなく最小・最大の列にも注目してください。
最小値は、そのモデルが出せる"真の限界性能"です。10回生成した中で最も良かった結果。つまり「運が良ければここまで出せる」という上限を示しています。
最大値は、そのモデルの"再現の不安定さ"を示します。10回中で最も悪かった結果。実務で使うとき、最悪このレベルの出力が来る可能性があるということです。
ブレ幅(最大 − 最小)は「信頼性指標」として読めます。たとえばOpus 4.5のブレ幅は約0.012、Gemini 3 Proは約0.042、GPT-5.1 Codexは約0.10。この数字が小さいほど「毎回同じ品質で返してくれる」信頼できるモデルということになります。
考察
スコア上はClaude Opus 4.5が優秀でした。
平均スコア0.0896という数字もさることながら、注目すべきは最小・最大の振れ幅です。Opus 4.5のスコア幅は0.0841〜0.0959、つまり±1%未満に収まっています。10回生成しても安定してほぼ同じクオリティが出る、というのは大きなアドバンテージです。
一方のGemini 3 Proは平均0.1083で2位につけましたが、最大0.1372まで振れることがありました。これは「当たり外れがある」ということを意味します。良いときはOpusに迫りますが、悪いときは明らかに劣ります。
GPT-5.1 Codex系はPro版(プレフィクスなし)がMini版より良いスコアですが、最大0.2を超えることもあり、ばらつきが大きすぎて信頼しづらい印象です。イテレーションによってはMini版の方が良い結果を出すこともありました。
Fast系モデル(Haiku、Codex Mini、Gemini 2.5 Flash)は軒並み0.12前後で団子状態。総じてピクセル単位の再現精度を求めるタスクには向いていないことが数字で確認できました。
モデルごとの特性を寸評
数字だけでなく、観測できたモデルの特性についても触れておきます。
Claude Opus 4.5
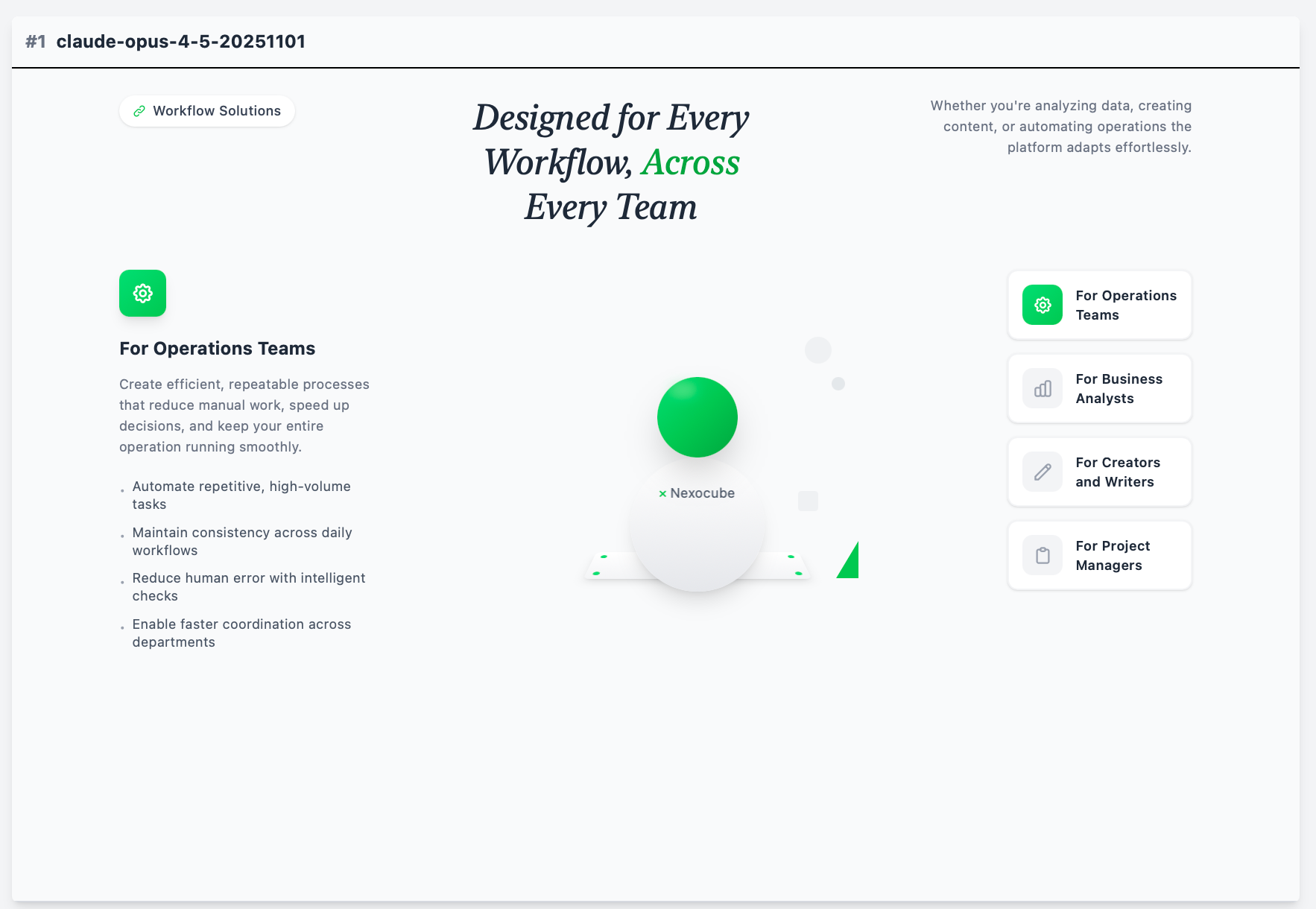
スコアのブレ幅がわずか0.012。「毎回ほぼ同じものを出す」という点で他を圧倒しています。なお、Sonnetを含めなかったのは忠実度テストではOpusが上位互換だろうという判断です。
Gemini 3 Pro
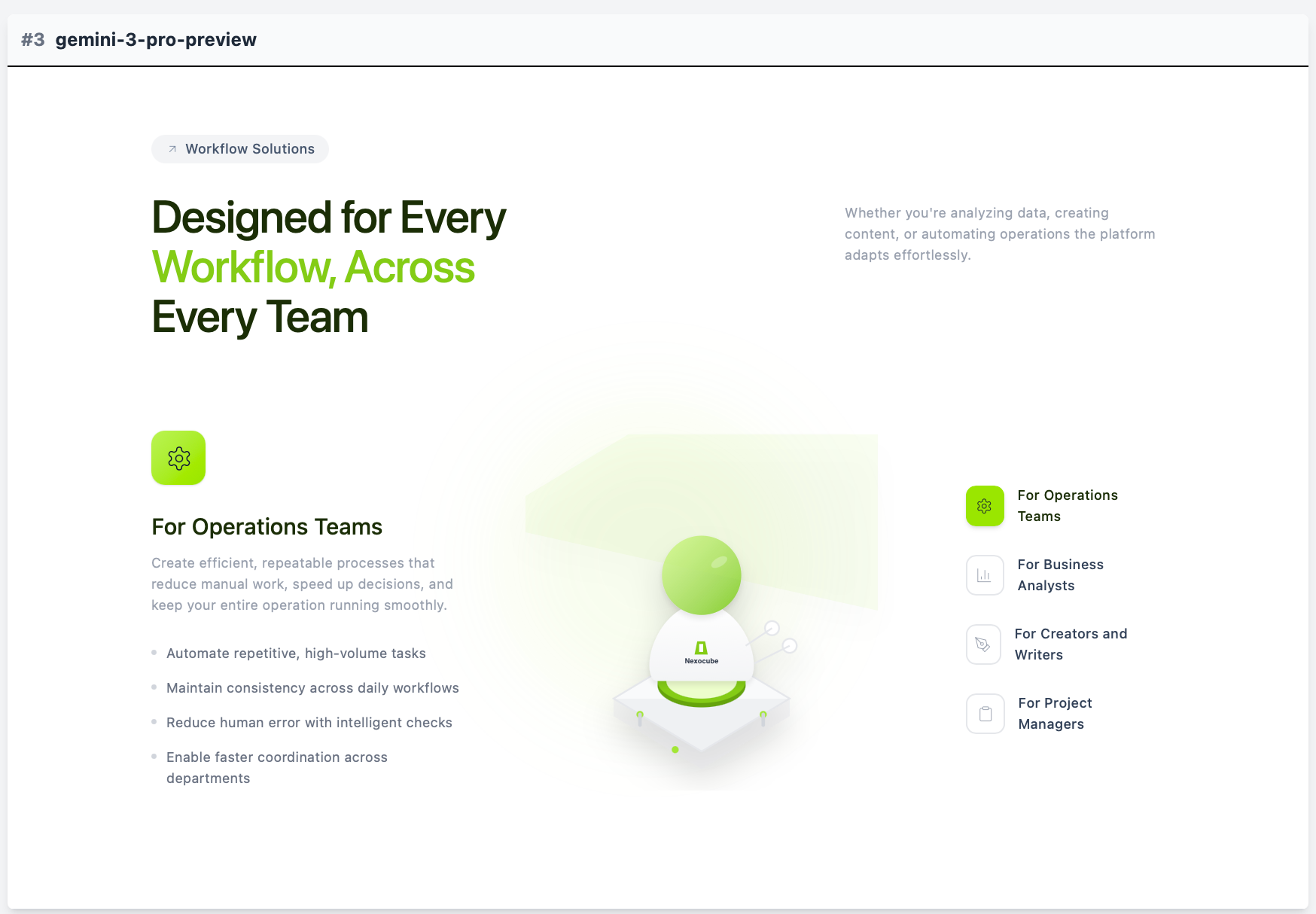
「視覚認識に強い」という定評通り、今回の検証でもOpusに迫る性能を見せました。しかし、安定性の面で一歩及ばなかったのが惜しい点です。2位という結果は悪くないですが、期待されていた「Opusを超える」という評判は今回の検証では確認できませんでした。
Nano Bananaが得意とするようなフォトジェニックな描写や他のGeminiのコンピュータビジョン向けのトレーニングで得た能力と、今回のような厳密なレイアウト調整能力との間に、相関性は薄いのかもしれません。
GPT-5.1 Codex

OpenAIのCodex系は「慎重で防御的なコード」を出すことで知られています。エッジケースを考慮した堅牢な実装、エラーハンドリングの丁寧さ——そうした美点はあるのですが、レイアウトの整合性という点では崩れやすい傾向がありました。
なお、GPT Proシリーズは今回含めていません。推論特化モデルで"長く深く考える"設計のため、UI再現のようなコード生成タスクには向いていないと判断しました。
Fast系モデル
速度優先のモデルたちが画素単位の精密タスクを苦手とするのは予想通りでした。ただし補足しておくと、前世代のGemini 2.5 Flashは同クラスの中ではかなり有能で、軽量モデルとしては健闘していた印象があります。今回のGemini 2.5 Flashも0.1228という数字はFast枠の中では悪くありません。
まとめ
「Gemini 3 ProがUIデザインで最強」という評判は、少なくとも今回の検証では実証できませんでした。
Claude Opus 4.5が依然としてUI再現度においてトップを維持しています。Gemini 3 ProやGPT-5.1 Codexも悪くはないですが、安定性という点でOpusには一歩及ばない、というのが筆者の印象です。
この検証の限界
今回測ったのは「1回の推論によるNext.js + TailwindでのUIコピー精度と安定性」だけです。創造性、対話的な改善能力、他フレームワークでの性能は評価していません。
なので「Opus 4.5がUI全般で最強」ではなく、「このタスクで最も安定して高精度だった」というのが正確なところです。
応用を考える
この検証方法が活きるユースケース:自動リデザイン、Figmaカンプからのコード生成、ビジュアルリグレッションテストなど。
データ取得方法は共通でモデルを差し替え可能にしているので、今後のアップデートや別のモデルにも適用できます。
実務では「このモデルは安定しているので1回で信頼できる」「発散しがちなモデルは複数回試して良い方を取る」といった判断も有効です。
おわりに
今回の検証手法は、筆者のようにデザインの専門的な素養が薄い人間でも、客観的な指標に基づいてモデルの能力を評価できるように工夫したものです。
今回の検証は pixelmatch による差分計測でしたが、より高度な研究としてはDesignBenchがあります。これはCLIPモデルを用いた意味的類似度の測定 や、専門家による人手やLLMによる視覚的評価を組み合わせて、コード生成時だけではなく編集タスクも対象に含めています。

こういう分野に関心があるので、もし他にも実施できそうな良いUI評価手法や、より効果的なベンチマークの方法をご存知の方がいれば、ぜひ教えていただけると嬉しいです。
おまけ:検証システムの詳細
今回の検証は、Next.jsプロジェクトをベースにした自動化パイプラインで実施しました。ソースコードはGistに公開しています。
技術スタック
- Next.js 16 + Tailwind CSS 4 — 生成コードの実行環境
- Vercel AI SDK — 複数モデルへの統一的なAPI呼び出し
- Playwright — スクリーンショット取得
- pixelmatch — 画像比較・差分算出
パイプライン構成
検証は以下の4つのスクリプトで構成されています。
/
├── generate-code.ts # 各モデルにUI画像を送信しコード生成
├── capture-screenshots.ts # 生成ページのスクリーンショット取得
├── compare-images.ts # pixelmatchで差分スコア算出
├── run-batch-experiment.ts # 上記を10回繰り返すバッチ処理
└── aggregate-scores.js # 全イテレーションのスコアを集計
generate-code.ts では、Vercel AI SDKの generateText を使い、6つのモデルに同じ画像とプロンプトを投げます。レスポンスからコードブロックを抽出し、pages/{model}/index.tsx に保存します。
capture-screenshots.ts では、Playwrightで http://localhost:3000/{model} にアクセスし、viewport 1440pxでスクリーンショットを取得します。
compare-images.ts では、基準画像と生成画像をpixelmatchで比較し、差分ピクセル数から0〜1のスコアを算出します。
run-batch-experiment.ts では、これらを10回繰り返し、各イテレーションの結果を batch_results/{timestamp}/iteration-{n}/ に保存します。